Data Policies Reference Guide
Data Policies in Immuta are managed and applied to data sources and projects by Data Owners and Governors to restrict access to data. Data Policies can be created both as Global Policies and Local Policies. Once a user is subscribed to a data source, the Data Policies that are applied to that data source determine what data the user sees. Data Policy types include masking, row redaction, and limiting to purpose.
Masking Policies
Masking policies hide values in data, providing various levels of utility while still preserving privacy. In order to create masking policies on object-backed data sources, you must create data dictionary entries and the data format must be either, csv, tsv, or json.
Hashing
This policy masks the values with an irreversible sha256 hash, which is consistent for the same value throughout the data source, so you can count or track the specific values, but not know the true raw value.
Hashed values are different across data sources, so you cannot join on hashed values unless you enable masked joins on data sources within a project. Immuta prevents joins on hashed values to protect against link attacks where two data owners may have exposed data with the same masked column (a quasi-identifier), but their data combined by that masked value could result in a sensitive data leak.
Replace with Null
This policy makes values null, removing any utility of the data the policy applies to.
Replace with Constant
With this policy, you can replace the values with the same constant value you choose, such as 'Redacted', removing any utility of that data.
Regular Expression (regex)
This policy is similar to replacing with a constant, but it provides more utility because you can retain portions of the true value. For example, the following regex rule would mask the final digits of an IP address:
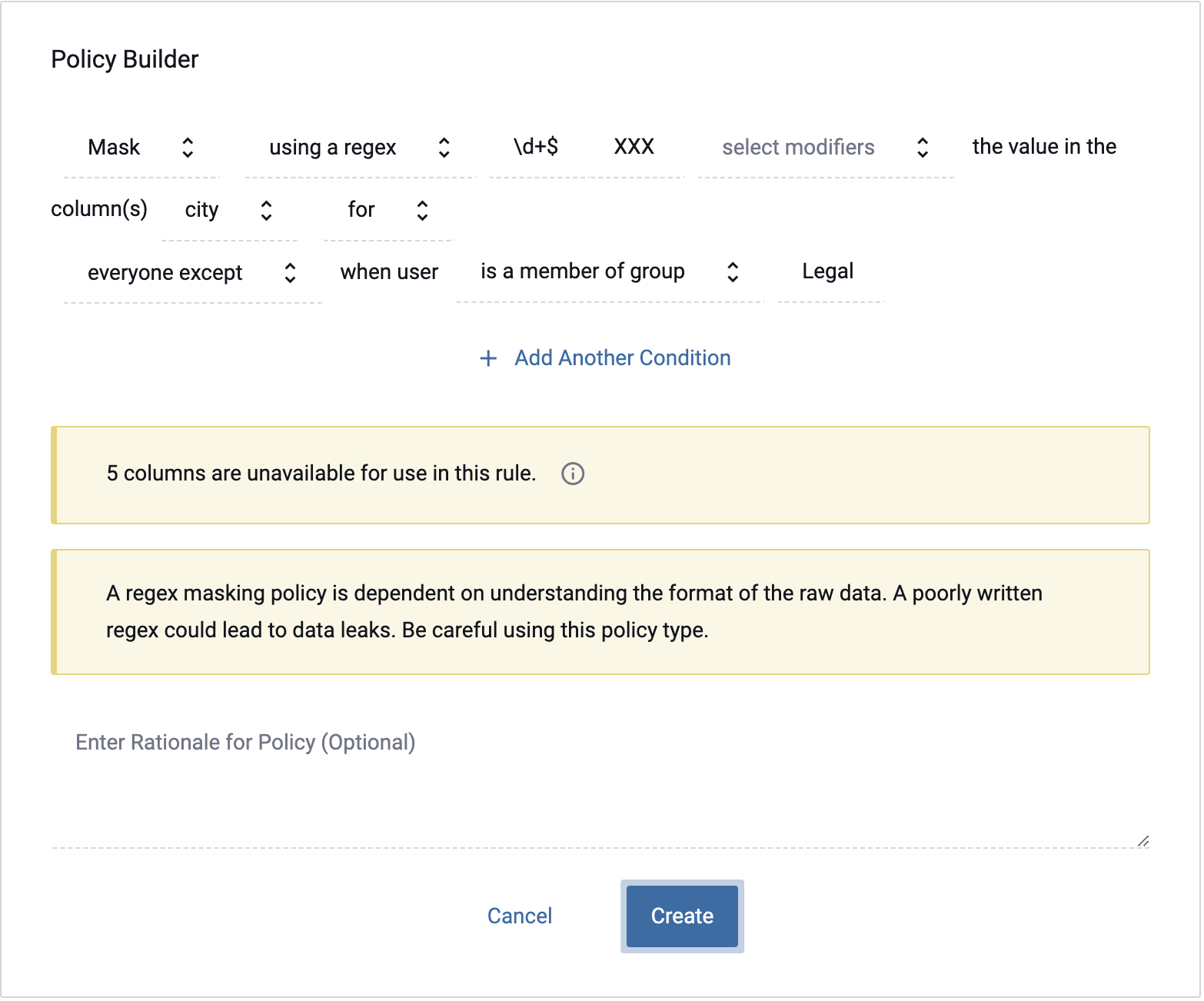
In this case, the regular expression \d+$
\d matches a digit (equal to [0-9])
+ Quantifier — Matches between one and unlimited times, as many times as possible, giving back as needed (greedy)
$ asserts position at the end of the string, or before the line terminator right at the end of the string (if any)
This ensures we capture the last digit(s) after the last . in the ip address. We
then can enter the replacement for what we captured, which in this case is XXX. So the
outcome of the policy, would look like this: 164.16.13.XXX
Rounding
This is a technique to hide precision from numeric values while providing more utility than simply hashing. For example, you could remove precision from a geospatial coordinate. You can also use this type of policy to remove precision from dates and times by rounding to the nearest hour, day, month, or year.
With Reversibility
This option masks the values using hashing, but allows users to submit an unmasking request to users who meet the exceptions of the policy.
Note: The user receiving the unmasking request must send the unmasked value to the requester.
With Reversible Masking, the raw values are switched out with consistent values to allow analysis without revealing the underlying sensitive data. The direct identifier is replaced with a token that can still be tracked or counted.

With Format Preserving Masking
This option masks the value, but preserves the length and type of the value, as illustrated in the examples below.


This option also allows users to submit an unmasking request to users who meet the exceptions of the policy.
Preserving the data format is important if the format has some relevance to the analysis at hand. For example, if you need to retain the integer column type or if the first 6 digits of a 12-digit number have an important meaning.
Custom Function
This option uses functions native to the underlying database to transform the column.

Limitations
- The masking functions are executed against the remote database directly. A poorly written function could lead to poor quality results, data leaks, and performance hits.
- Using custom functions can result in changes to the original data type. In order to prevent query errors you must ensure that you cast this result back to the original type.
-
The function must be valid for the data type of the selected column. If it is not
- Local policies will error and show a message that the function is not valid.
- Global policies will error and change to the default masking type (hashing for text and NULL for all others).
Conditionally Masking
For all of the policies above, both at the Local and Global Policy levels, you can conditionally mask the value based on a value in another column. This allows you to build a policy that looks something like: "Mask bank account number where country = 'USA'" instead of blindly stating you want bank account masked always.
Note: When building conditional masking policies with custom SQL statements, avoid using a column that is masked using randomized response in the SQL statement, as this can lead to different behavior depending on whether you’re using the Query Engine, Spark, or Snowflake and may produce results that are unexpected.
With K-Anonymization
K-anonymity is measured by grouping records in a data source that contain the same values for a common set of quasi identifiers (QIs) - publicly known attributes (such as postal codes, dates of birth, or gender) that are consistently, but ambiguously, associated with an individual.
The k-anonymity of a data source is defined as the number of records within the least populated cohort, which means that the QIs of any single record cannot be distinguished from at least k other records. In this way, a record with QIs cannot be uniquely associated with any one individual in a data source, provided k is greater than 1.
In Immuta, masking with K-Anonymization examines pairs of values across columns and hides groups that do not
appear at least the
specified number of
times (k). For example, if one column contains street numbers and another contains street names, the group
123, "Main Street" probably would appear frequently while the group 123, "Diamondback Drive" probably would show up
much less. Since the second group appears infrequently, the values could potentially identify someone, so this group
would be masked.
After the fingerprint service identifies columns with a low number of distinct values, users will only be able to select those columns when building the policy. Users can either use a minimum group size (k) given by the fingerprint or manually select the value of k.

Note: The default cardinality cutoff for columns to qualify for k-anonymization is 500. For details about adjusting this setting, navigate to the App Settings Tutorial.
Masking Multiple Columns with K-Anonymization
Governors can write Global Data Policies using K-Anonymization in the Global Data Policy Builder.

When this Global Policy is applied to data sources, it will mask all columns matching the specified tag.
Warning
Applying k-anonymization over disjoint sets of columns in separate policies does not guarantee k-anonymization over their union.
If you select multiple columns to mask with K-Anonymization in the same policy, the policy is driven by how many times these values appear together. If the groups appear fewer than k times, they will be masked.
For example, if Policy A
Policy A: Mask with K-Anonymization the values in the columns
genderandstaterequiring a group size of at least 2 for everyone
was applied to this data source
| Gender | State |
|---|---|
| Female | Ohio |
| Female | Florida |
| Female | Florida |
| Female | Arkansas |
| Male | Florida |
the values would be masked like this:
| Gender | State |
|---|---|
| Null | Null |
| Female | Florida |
| Female | Florida |
| Null | Null |
| Null | Null |
Note: Selecting many columns to mask with K-Anonymization increases the processing that must occur to calculate the policy, so saving the policy may take time.
However, if you select to mask the same columns with K-Anonymization in separate policies, Policy C and Policy D,
Policy C: Mask with K-Anonymization the values in the column
genderrequiring a group size of at least 2 for everyonePolicy D: Mask with K-Anonymization the values in the column
staterequiring a group size of at least 2 for everyone
the values in the columns will be masked separately instead of as groups. Therefore, the values in that same data source would be masked like this:
| Gender | State |
|---|---|
| Female | Null |
| Female | Florida |
| Female | Florida |
| Female | Null |
| Null | Florida |
Using Randomized Response
This policy masks data by slightly randomizing the values in a column, preserving the utility of the data while preventing outsiders from inferring content of specific records.
For example, if an analyst wanted to publish data from a health survey she conducted, she could remove direct identifiers and apply k-anonymization to indirect identifiers to make it difficult to single out individuals. However, consider these survey participants, a cohort of male welders who share the same zip code:
| participant_id | zip_code | gender | occupation | substance_abuse |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
880d0096 |
75002 | Male | Welder | Y |
f267334b |
75002 | Male | Welder | Y |
bfdb43db |
75002 | Male | Welder | Y |
260930ce |
75002 | Male | Welder | Y |
046dc7fb |
75002 | Male | Welder | Y |
| ... | ... | ... | ... | ... |
All members of this cohort have indicated substance abuse, sensitive personal information that could have damaging consequences, and, even though direct identifiers have been removed and k-anonymization has been applied, outsiders could infer substance abuse for an individual if they knew a male welder in this zip code.
In this scenario, using randomized response would change some of the Y's in substance_abuse to N's and vice versa;
consequently, outsiders couldn't be sure of the displayed value of substance_abuse given in any individual row,
as they wouldn't know which rows had changed.
How the Randomization Works
Immuta applies a random number generator (RNG) that is seeded with some fixed attributes of the data source, column, backing technology, and the value of the high cardinality column, an approach that simulates cached randomness without having to actually cache anything.
For string data, the random number generator essentially flips a biased coin. If the coin comes up as tails, which it does with the frequency of the replacement rate configured in the policy, then the value is changed to any other possible value in the column, selected uniformly at random from among those values. If the coin comes up as heads, the true value is released.
For numeric data, Immuta uses the RNG to add a random shift from a 0-centered Laplace distribution with the standard deviation specified in the policy configuration. For most purposes, knowing the distribution is not important, but the net effect is that on average the reported values should be the true value plus or minus the specified deviation value.
Preserving Data Utility
Using randomized response doesn't destroy the data because data is only randomized slightly; aggregate utility can be preserved because analysts know how and what proportion of the values will change. Through this technique, values can be interpreted as hints, signals, or suggestions of the truth, but it is much harder to reason about individual rows.
Additionally, randomized response gives deniability of record content not dataset participation, so individual rows can be displayed.
Mixing Masking Policies on the Same Column
In some cases, you may want several different masking policies applied to the same column through Otherwise policies. To build these policies, select everyone who instead of everyone or everyone except. After you specify who the masking policy applies to, select how it applies to everyone else in the Otherwise condition.

You can add and remove tags in Otherwise conditions for Global policies (unlike Local policy Otherwise conditions), as illustrated above; however, all tags or regular expressions included in the initial everyone who rule must be included in an everyone or everyone except rule in the additional clauses.

SQL Support Matrix
The SQL Support Matrix button in the Data Policies section allows users to view all masking policy types and details what is supported for each integration.

Complex Data Types: Masking Fields within Struct Columns (Public Preview)
Feature Limitations
- Masking struct and array columns is only available for Databricks data sources.
- Immuta only supports Parquet and Delta table types.
- If the table is queried through the Query Engine instead of natively in Databricks, any struct fields that have an applied masking policy will have the root struct column made null.
Spark supports a class of data types called complex types, which can represent multiple data values in a single column. Immuta supports masking fields within array and struct columns:
- array: an ordered collection of elements
- struct: a collection of elements that are primitive or complex types
Without this feature enabled, the struct and array columns of a data source default to jsonb in the Data Dictionary,
and the masking policies that users can apply to jsonb columns are limited. For example, if a user wanted to mask PII
inside the column patient in the image below, they would have to apply null masking to the entire column or use a
custom function instead of just masking name or address.

After Complex Data Types is enabled on the
App Settings page,
the column type for struct columns for new data sources will display as struct in the Data
Dictionary. (For data sources that are already in Immuta, users can edit the data source and change the column types
for the
appropriate columns from jsonb to struct.) Once struct fields are available, they can be
searched, tagged, and used in masking policies. For example,
a user could tag name, ssn, and street as PII instead of the entire patient column.
After a Global or Local policy masks the columns containing PII, users who do not meet the exception specified in the policy will see these values masked:

Note: Immuta uses the > delimiter to indicate that a field is nested instead of the . delimiter, since field and
column names could include ..
Caveats
Struct Columns with Many Fields
If users have struct columns with many fields, they will need to either
- create the data source against a cluster running Spark 3 or
- add
spark.debug.maxToStringFields 1000to their Spark 2 cluster's configuration.
To get column information about a data source, Immuta executes a DESCRIBE call for the table. In this call, Spark
returns a simple string representation of the schema for each column in the table. For the patient column above, the
simple string would look like this:
struct<name:string,ssn:string,age:int,address:struct<city:string,state:string,zipCode:string,street:text>>
Immuta then parses this string into the following format for the data source's dictionary:
{
dataType: 'struct',
children: [
{
name: 'name',
dataType: 'text'
},
{
name: 'ssn',
dataType: 'text'
},
{
name: 'age',
dataType: 'integer'
},
{
name: 'address',
dataType: 'struct',
children: [
{
name: 'city',
dataType: 'text'
},
{
name: 'state',
dataType: 'text'
},
{
name: 'zipCode',
dataType: 'text'
},
{
name: 'street',
dataType: 'text'
},
]
}
]
}
However, if the struct contains more than 25 fields, Spark truncates the string, causing the parser to fail and
fall back to jsonb. Immuta will attempt to avoid this failure by increasing the number of fields allowed
in the server-side property setting, maxToStringFields; however, this only works with clusters on a Spark 3 runtime.
The maxToStringFields configuration in Spark 2 cannot be set through the ODBC driver and can only be set
through the Spark configuration on the cluster with spark.debug.maxToStringFields 1000 on cluster startup.
External Masking
Warning
Immuta’s External Masking feature expects data to be masked at rest by an external tool consistently on a per-cell basis in the remote database. Immuta then provides policy-based unmasking (and additional masking on top of this using standard masking policies) through the Query Engine.
This feature allows Immuta to unmask data that is masked at rest in a remote database using a customer-provided encryption or masking algorithm. To do so,
- System Administrators build their own custom logic and security in an external REST service. Because Immuta always pushes down the masked version of the literal when the user is exempt from the policy, the organization should use deterministic IVs/salt to ensure the same value is masked consistently throughout the data.
- System Administrators give Immuta access to the external REST service and configure tags that will be used by Data Owners to indicate that data is masked at rest in the remote database.
- Data Owners apply these tags to columns that are masked (with encryption or another algorithm) in the remote database.
- Data Owners or Governors create data policies that allow Immuta to reach out to this external REST service to unmask data according to the specifications in the policy.
Unmasking Process
Immuta will only unmask externally masked data if two conditions are met:
- A masking policy is applied against that tagged column.
- The querying user is exempt from that policy.
When a user who is exempt from the policy restrictions queries that masked column using a filter, Immuta converts the literal being queried using the external algorithm provided. Consider the following example:
- The
social_security_numbercolumn is masked on-ingest and has the tagexternally_masked_dataapplied to it. - This masking policy is applied to the data source in Immuta: Mask using hashing the values in the column tagged
externally_masked_dataexcept for users who belong to the groupview_masked_values. - The querying user belongs to the
view_masked_valuesgroup.
When the user above runs the query select * from table A where social_security_number = 220869988,
Immuta converts 220869988 to the masked value using the provided algorithm to query the database and return matching
rows.
Use Equality Queries Only
Queries against masked values on-ingest should be equality queries only. For example, if an exempt user
ran a query like select * from table A where social_security_number > 220869988, the results may not make sense
(depending on the algorithm used for masking the data).
Tutorials
- To configure External Masking, see the App Settings Tutorial.
- For an implementation guide, see the External Masking Interface.
Row-Level Security Policies
These policies hide entire rows or objects of data based on the policy being enforced; some of these policies require the data to be tagged as well.
Note: When building row-level policies with custom SQL statements, avoid using a column that is masked using randomized response in the SQL statement, as this can lead to different behavior depending on whether you’re using the Query Engine, Spark, or Snowflake and may produce results that are unexpected.
Matching
These policies match a user attribute with a row/object/file attribute to determine if that row/object/file should be visible. This process uses a direct string match, so the user attribute would have to match exactly the data attribute in order to see that row of data.
For example, to restrict access to insurance claims data to the state for which the user's home office is located, you could build a policy such as this:
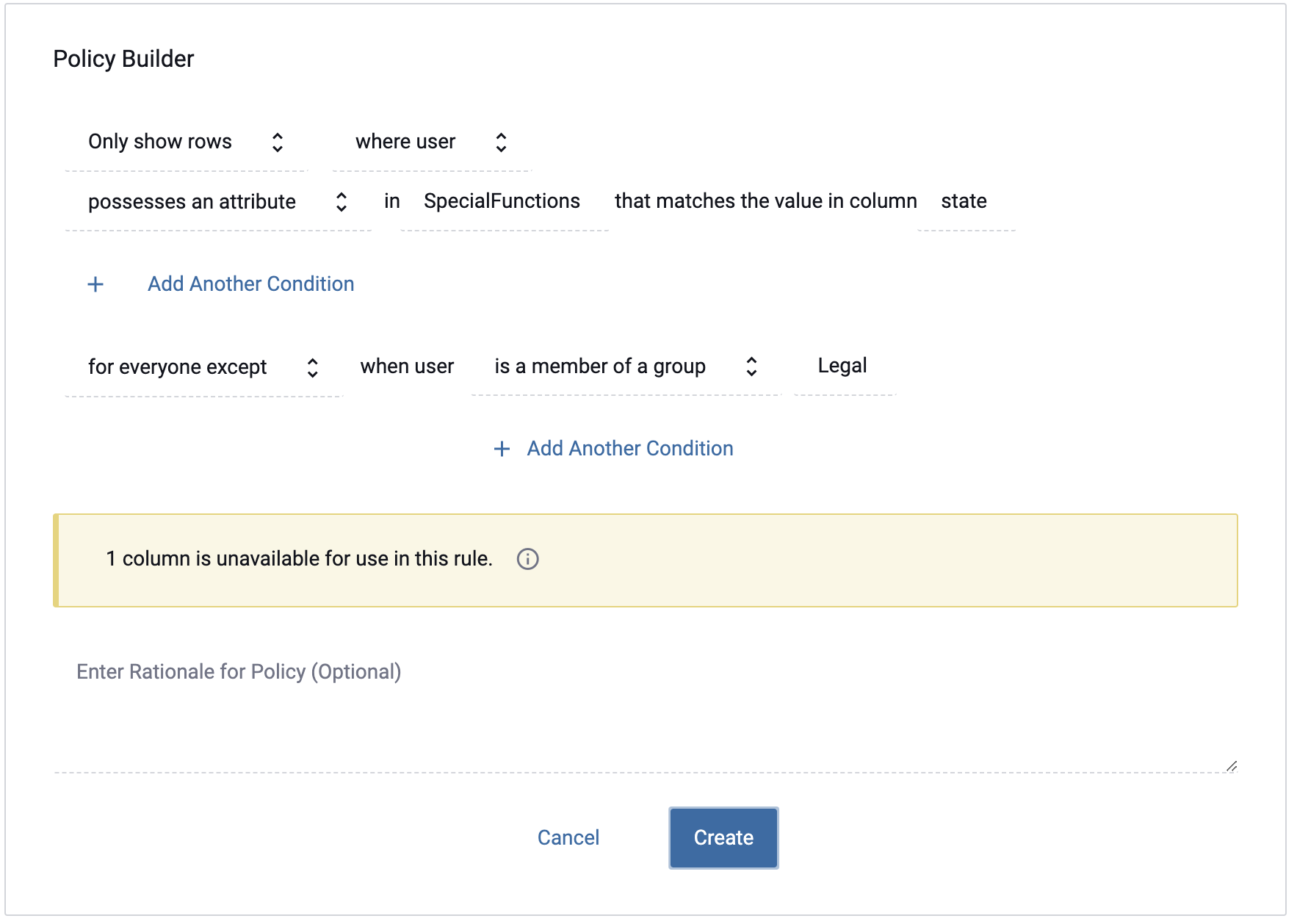
In this case, the Office Location is retrieved by the identity
management system as a user attribute or group. If the user's attribute
(Office Location) was Missouri, rows containing the value Missouri in the State column
in the data source would be the only rows visible to that user.
For object-backed sources, the State can be retrieved from places
other than columns, depending on the database. For example, in S3 it is
retrieved from the metadata or tags on the S3 object or the folder name. For HDFS it is
retrieved from the xattr on the file or the folder name.
WHERE Clause Policy
This policy can be thought of as a table "view" created automatically for the user based on the condition of the policy.
For example, in the policy below, users who are not members of the Admins group will only see taxi rides where passenger_count < 2.
Only show rows where
public.us.taxis.passenger_count <2for everyone except when user is a member of group Admins.
You can put any valid SQL WHERE clause in the policy. See the Custom WHERE clause functions for a list of custom functions.
WHERE clause policy requirement
All columns referenced in the policy must have fully qualified names. Any column names that are unqualified (just the column name) will default to a column of the data source the policy is being applied to (if one matches the name).
Time-Based Restrictions
These policies restrict access to rows/objects/files that fall within the time restrictions set in the policy. If a
data source has time-based restriction policies, queries run against the data source by a user will only
return rows/blobs with a date in its event-time column/attribute from within a certain range.
This type of policy can be used for both object-backed and query-backed data sources.
The time window is based on the event time you select when creating the data source. This value will come from a date/time column in relational sources. For S3 it can be retrieved by a metadata or tag on the S3 object, and for HDFS it is retrieved from the xattr on the file.
Minimization
These policies return a limited percentage of the data, which is randomly sampled, at query time. but it is the same sample for all the users. For example, you could limit certain users to only 10% of the data. Immuta uses a hashing policy to return approximately 10% of the data, and the data returned will always be the same; however, the exact number of rows exposed depends on the distribution of high cardinality columns in the database and the hashing type available. Additionally, Immuta will adjust the data exposed when new rows are added or removed. This policy can only be applied to query-backed data sources.
Best Practice: Row Count
Immuta recommends you use a table with over 1,000 rows for the best results when using a data minimization policy.
Limit to Purpose
Purposes help define the scope and use of data within a project and allow users to meet purpose restrictions on policies. Governors create and manage purposes and their sub-purposes, which project owners then add to their project(s) and use to drive Data Policies.
Purposes can be constructed as a hierarchy, meaning that purposes can contain nested sub-purposes, much like tags in Immuta. This design allows more flexibility in managing purpose-based restriction policies and transparency in the relationships among purposes.
For example, consider this organization of the sub-purposes of Research:
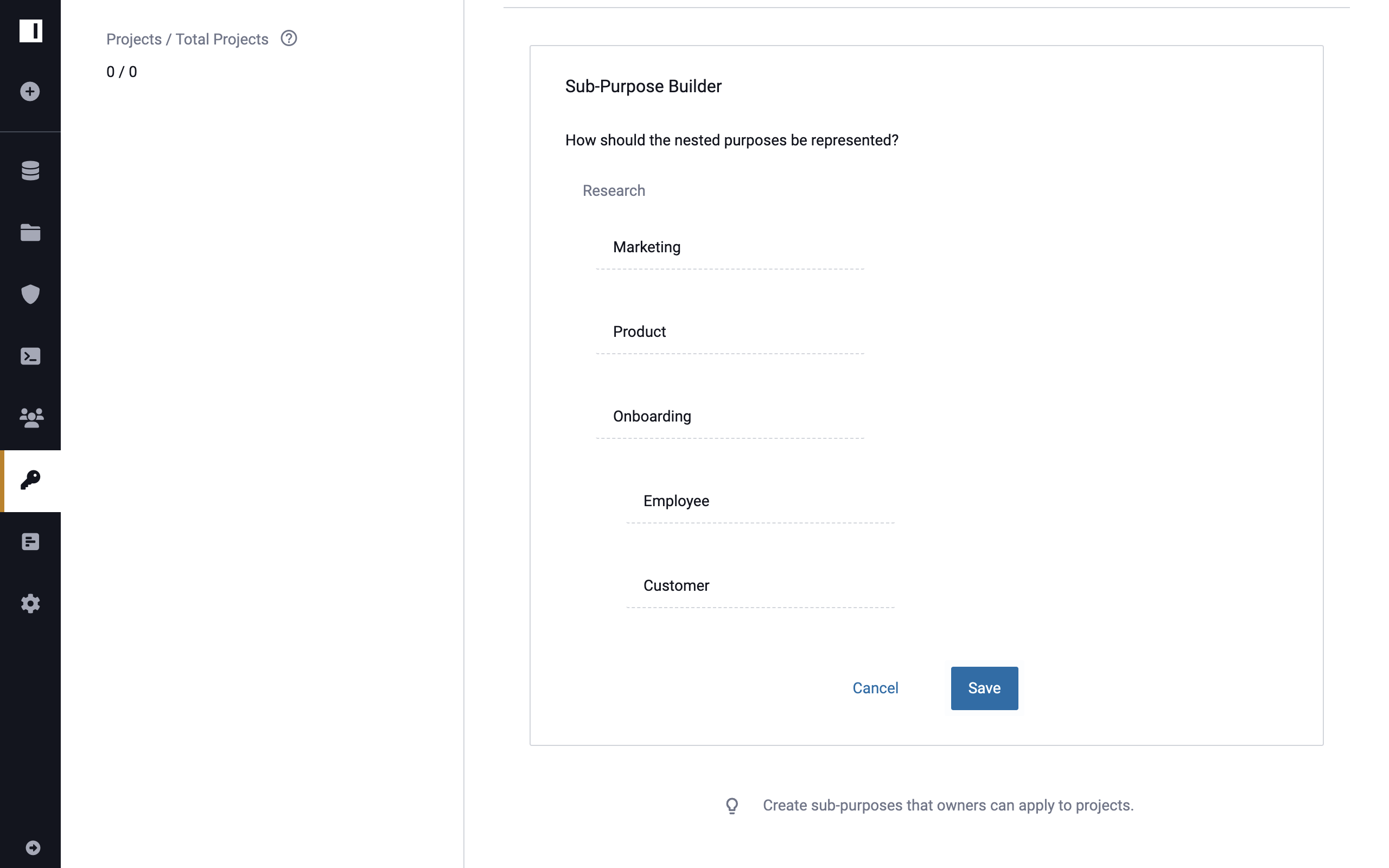
Instead of creating separate purposes, which must then each be added to policies as they evolve, a Governor could write the following Global Policy:
Limit usage to purpose(s) Research for everyone on data sources tagged PHI.
Now, any user acting under the purpose or sub-purpose of Research - whether Research.Marketing or
Research.Onboarding.Customer - will meet the criteria of this policy. Consequently,
purpose hierarchies eliminate
the need for a Governor to re-write these Global Policies when sub-purposes are added or removed. Furthermore, if new
projects with new Research purposes are added, for example, the relevant Global Policy will automatically be enforced.
Please refer to the Data Governor Policy Guide for a tutorial on purpose-based restrictions on data.
Conditions
For all of the rules above, you must also establish the conditions for which they will be enforced. Immuta allows you to append multiple conditions to the data. Those conditions are based on user attributes and groups (which can come from your identity management system), or purposes they are acting under via Immuta projects. Note that the attributes and groups can be retrieved from multiple different identity management systems and applied as conditions to the same policy.
Conditions can be directed as exclusionary or inclusionary, depending on the policy that's being enforced. Immuta has determined the best direction for the condition to avoid inadvertent data leaks.
For example, rather than specifying every user attribute that should see the unmasked value, you instead
specify the "special" attribute that is allowed to see the unmasked value, e.g. mask for everyone except. This
is exclusionary. There are inclusionary policies, such as row level security matching, where
you require that the user attribute matches the data attribute.
One final note on purposes. It's best to think about projects and purposes as additional entitlements for users. In other words, you would use projects to open users up to more data, not restrict them from more.
Data Policy Conflicts
In some cases, two conflicting Global Data Policies may apply to a single data source. When this happens, the policy containing a tag deeper in the hierarchy will apply to the data source to resolve the conflict.
Consider the following Global Data Policies created by a Data Governor:
Data Policy 1: Mask columns tagged
PIIby making null for everyone on data sources with columns taggedPIIData Policy 2: Mask columns tagged
PII.SSNusing hashing for everyone on data sources with columns taggedPII.SSN
If a Data Owner creates a data source and applies the PII.SSN tag, both of these Global Data Policies
will apply. Instead of having a conflict, the policy containing a deeper tag in the hierarchy will apply:

In this example, Data Policy 2 cannot be applied to the data source. If Data Owners wanted to use Data Policy 2 on the data source instead, they would need to disable Data Policy 1.
Once enabled on a data source, Global Data Policies can be edited and disabled by Data Owners. See the Local Policy Builder Tutorial for instructions.
Restricted Global Policies
Data Owners who are not Governors can write Restricted Global Policies for data sources that they own. With this feature, Data Owners have higher-level policy controls and can write and enforce policies on multiple data sources simultaneously, eliminating the need to write redundant Local Policies on data sources.
Unlike Global Policies, the application of these policies is restricted to the data sources owned by the users or groups specified in the policy and will change as users' ownerships change.
Staged Global Policies
Governors can create Staged Global Policies, which can then be safely reviewed and edited without affecting data sources. Once a policy is ready, Governors can activate it to immediately enforce the policy on relevant data sources.
Note: Policies that contain the circumstance When selected by data owners cannot be staged.

Global Data Policy Custom Certifications
When building a Global Data Policy, Governors can create custom certifications , which must then be acknowledged by Data Owners when the policy is applied to data sources.
When a Global Data Policy with a custom certification is cloned, the certification is also cloned. If the user who clones the policy and custom certification is not a Governor, the policy will only be applied to data sources that user owns.