Configure Sensitive Data Discovery (Public Preview)
Audience: Data Owners and Data Governors
Content Summary: This feature allows users to customize how sensitive data is detected and what tags are applied to that data.
Overview
Sensitive Data Discovery (SDD) comprises two major elements: Classifiers and Templates.
Classifiers
The classifier is the basic building block of SDD. Essentially, a classifier includes a pattern (e.g., a regex or a list of values) and a list of tags to apply to data that matches that pattern. For example, if a column sample matches a regex defined in a classifier, then all the tags in that classifier will be applied to that column.
SDD applies classifiers to samples of data to assess the likelihood that columns contain data that fits the pattern specified in the classifier (such as a social security number). SDD then scores columns by the percentage of values that match the pattern defined. This score determines whether or not the configured tags will be applied to a column.
There are two types of classifiers:
-
Built-in Classifiers: These classifiers are included with Immuta and detect common categories of sensitive data (such as social security numbers, zip codes, and routing numbers) and cannot be modified. Users can list built-in classifiers through the Immuta API or view this Built-In Classifiers Reference page.
-
Custom Classifiers: Custom classifiers allow Data Governors to create their own regular expressions, dictionaries, and tags that SDD will use to detect sensitive data.
By default, all classifiers are matched against data sources when SDD is triggered, unless a template (defined below) is applied to a data source.
Custom Classifier Types
The three types of custom classifiers are described in the table below.
| Custom Classifier Type | Definition | Use Case |
|---|---|---|
| Regex Classifier | This classifier contains a case-insensitive regular expression that allows users to match a custom regex against column values. | If the built-in classifiers do not contain a regex that could match against values within your data sources, use this classifier to create your own regex. See Create a Regex Classifier for a specific use case example. |
| Column Name Regex Classifier | This classifier includes a case-insensitive regular expression that is only matched against column names, not against the values in the column. | If a column name clearly denotes that it contains sensitive data, you could create this classifier to match the regex against the name of columns instead of the column values. See Create a Column Name Regex Classifier for a specific use case example. |
| Dictionary Classifier | This classifier contains a list of words and phrases to match against column values. | Create a dictionary classifier if there are words or phrases included in your datasets that may be sensitive, but will not be detected by the built-in classifiers. See Create a Dictionary Classifier for a specific use case example. |
Templates
A template is a collection of classifiers and settings that drive the configuration of SDD runs. The settings users can apply through templates include
- classifiers: The classifier(s) to apply to data sources in the SDD run.
- minConfidence: Optional override for the
minConfidenceestablished in the classifier(s). When the detection confidence is at least the percentage defined inminConfidence, tags are applied. - tags: Optional override for the tags applied by the classifier.
- sample size: Optional override for how many records to sample from the data source.
Users may apply a template globally or to a specific set of data sources. When SDD is triggered on a data source, it will use the classifiers and settings in its configured template to run the detection job. If no template has been configured, SDD will use the global settings, described below. By default, the global settings will use all classifiers in the system to run the detection.
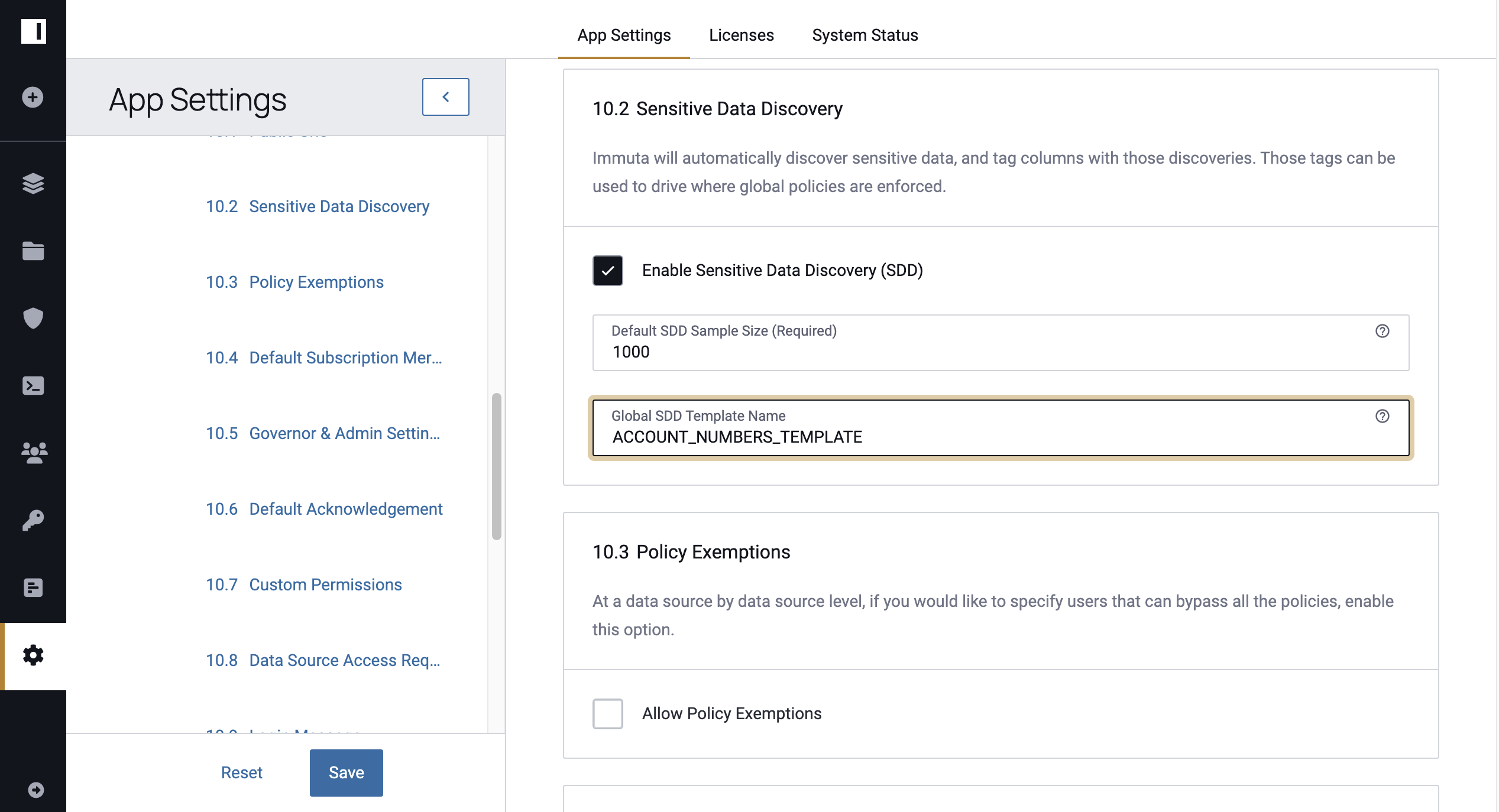
SDD Global Settings
Global Template
When SDD is triggered on a data source, classifiers in the template applied to it run the detection job, while data sources without a template applied to them will have the classifiers or template defined in the global settings run the detection job. By default, the global setting will use all classifiers in the system to run the detection. However, a System Administrator can configure Immuta to use a global template to run the detection instead. While a template is actively global, it cannot be deleted by users.
Sample Size
SDD applies a classifier to a sample of data to assess the likelihood that a column contains data that fits the pattern specified in the classifier.
By default, SDD samples 1000 records (the sample size) during this process. However, Administrators can configure the sample size taken by SDD on the App Settings page. In general, increasing the sample size increases the accuracy of SDD predictions, but decreasing the number of records sampled during SDD may be necessary to meet some organizations' compliance requirements.
Running SDD
SDD runs automatically when users create a new data source or when a new column is detected through schema monitoring, but users can also trigger SDD in the Immuta UI, through the Immuta CLI, or through the API.
Dry Run
Users can also configure SDD to do a dryRun, which allows them to see what tags would be applied to a data source
without actually applying them. See the
Run Sensitive Data Discovery on Data Sources tutorial
for details.
Tag Mutability
When SDD is triggered by a Data Owner, all column tags that were previously applied by SDD are removed and the tags prescribed by the latest run are applied, but if SDD is triggered because a new column is detected by schema monitoring, no tags will be modified on existing columns.
SDD Workflow
Two common workflows for using SDD are outlined below. The first illustrates how to apply a single global template to all data sources, while the second outlines how users can create and apply templates to data sources they own.
Workflow 1: Apply a Global Template to All Data Sources
- Data Governor creates a template using one or more built-in or custom classifiers.
- System Administrator adds this template to the global settings so that it applies to all data sources.
- Users trigger SDD on data sources.
Workflow 2: Apply a Template to a Specific Data Source
- Data Governor creates one or more custom classifiers:
- Data Owner creates a template containing one or more classifiers.
- Data Owner applies their template to one or more data sources.
- Data Owner triggers SDD on one or more data sources, and tags are applied to columns where sensitive data was detected.