Policy Adjustments (Public Preview)
Audience: Project Owners
Content Summary: This page outlines the Policy Adjustment feature.
This Public Preview feature must be enabled on the App Settings page.
Policy Adjustments
Project owners can use Policy Adjustments to increase a data set's utility while retaining the amount of k-anonymization that upholds de-identification requirements. With this feature enabled, users can redistribute the noise across multiple columns of a data source within a project to make specific columns more useful for their analysis. Since these adjustments only occur within the project and do not change the individual Data Policies, data users must be acting under the project to see the adjustments in the data source.
Navigate to Adjust a Policy for a tutorial.
Policy Adjustment Example
The data source below masks these columns with k-anonymization: Income, Education, EmploymentStatus,
Gender, and Location Code. When the analyst examines the data, the percent NULL has been predetermined by Immuta
with an equal weight across all of these columns. However, if the analyst's work hinges on the EmploymentStatus
column, the project owner can adjust the weights on the Policy Adjustment tab in the project to make the necessary
data (EmploymentStatus) less NULL.
Here the default weight has been equalized across the columns giving the same amount of importance to all of the data, allocating the noise to allow the most use possible across all of the masked columns.
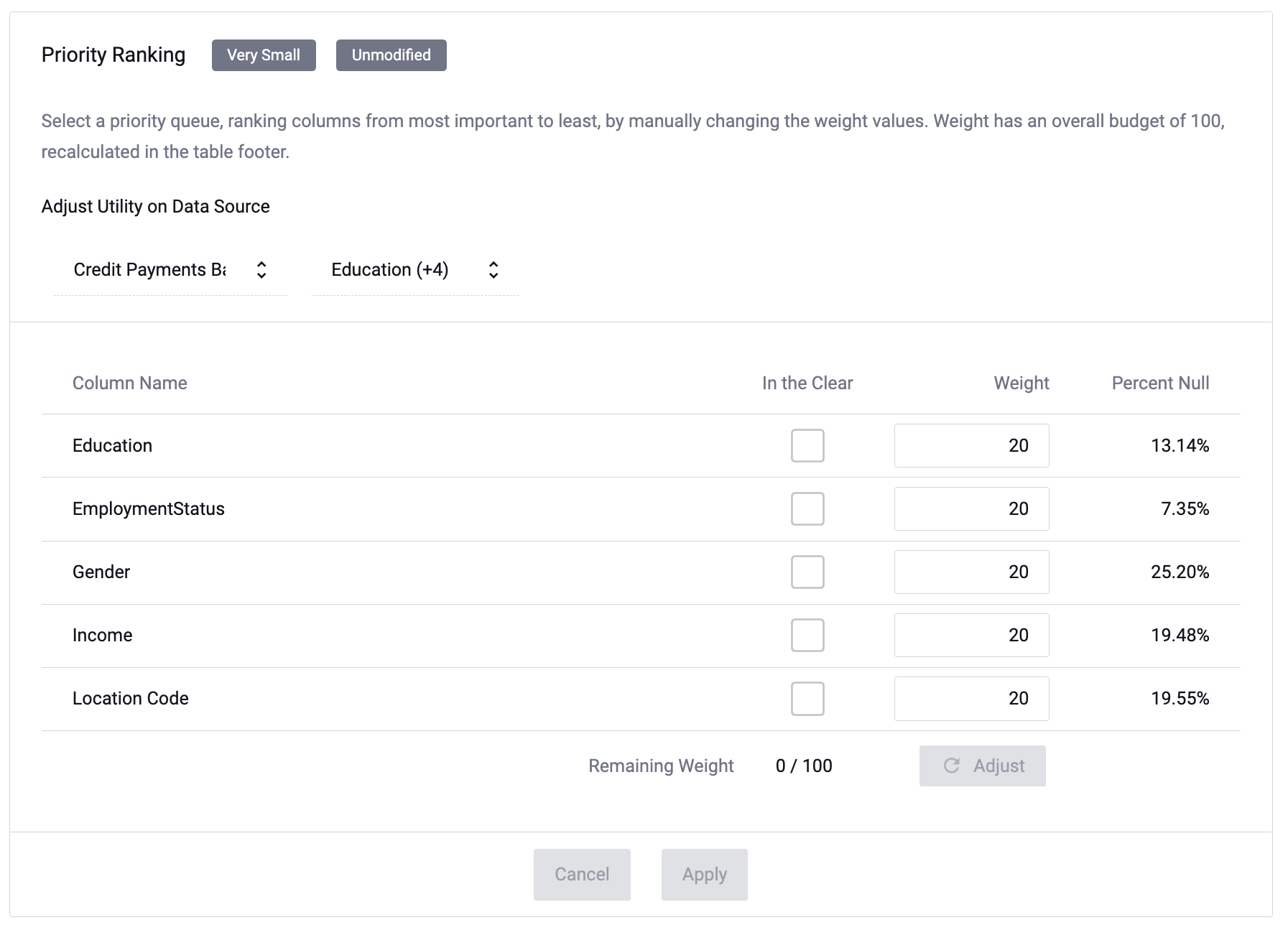
Here the weight is manually adjusted to lower the percent NULL and make the needed column (EmploymentStatus) more
usable while still retaining the necessary amount of de-identification by redistributing the noise across the
other columns.
Weight Distribution and Percent Null
For columns that are already well-disclosed (have a low Percent Null), the same Percent Null will display even when you drastically change the weight distribution, as illustrated in a comparison of the two images below:
Even Weight Distribution
The weight is evenly distributed among all columns in this image, and the Percent Null is visible for each of these k-anonymized columns.

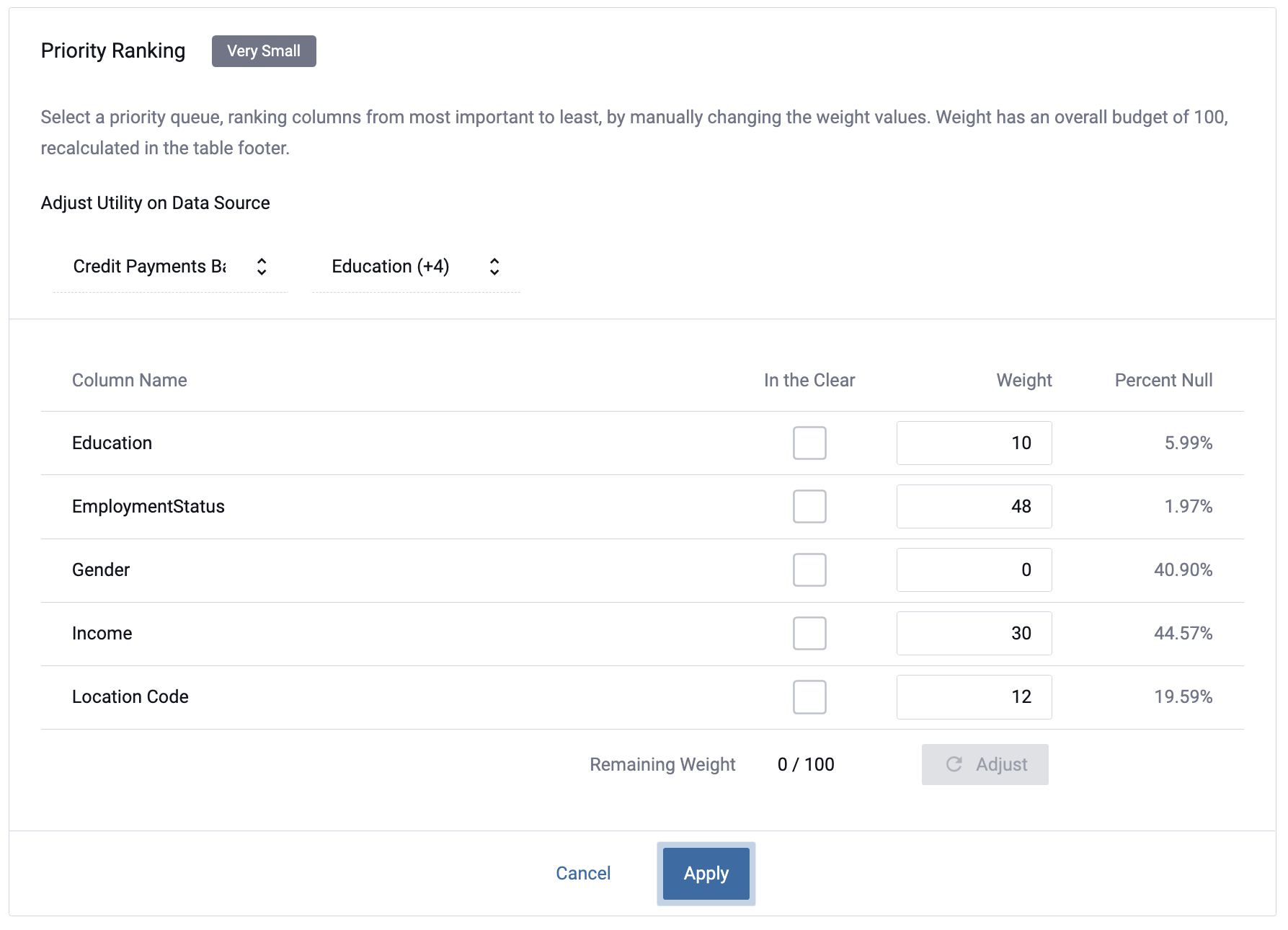
Adjusted Weight Distribution
Even though the weight of the c_birth_year column has been changed to 97, the value in Percent Null remains the same.

Increasing the weight of a column that is already well-disclosed (like c_birth_year in the example above) will not
change the outcome. Generally, the biggest impact will be seen when you increase the weights of the largest
Percent Null column. (The only exception to this is if that column already has a lot of native nulls in the
remote database.)
For example, shifting the weight to the column c_birth_day (which has a large percent null in the example above)
creates a bigger impact on the Percent Null:

Keep Fields in the Clear
This feature provides an Allow Fields in the clear option in the create purpose modal, permitting specified analysts to bypass k-anonymization in specific circumstances.
When any purpose with the Allow Fields in the clear property enabled is approved for use within a project, a project member can proceed through the policy adjustment workflow and specify columns to be unmasked. However, the seeded purpose Re-identification Prohibited.Expert Determination.DUAM is specific to HIPAA Expert Determination and automatically has the Show fields in the clear functionality enabled.
Navigate to Adjust a Policy for a tutorial.
Keep Fields in the Clear Example
Consider the following example, which illustrates a data source whose countrycode column has been selected to be
In the Clear and whose customerid column remains k-anonymized:
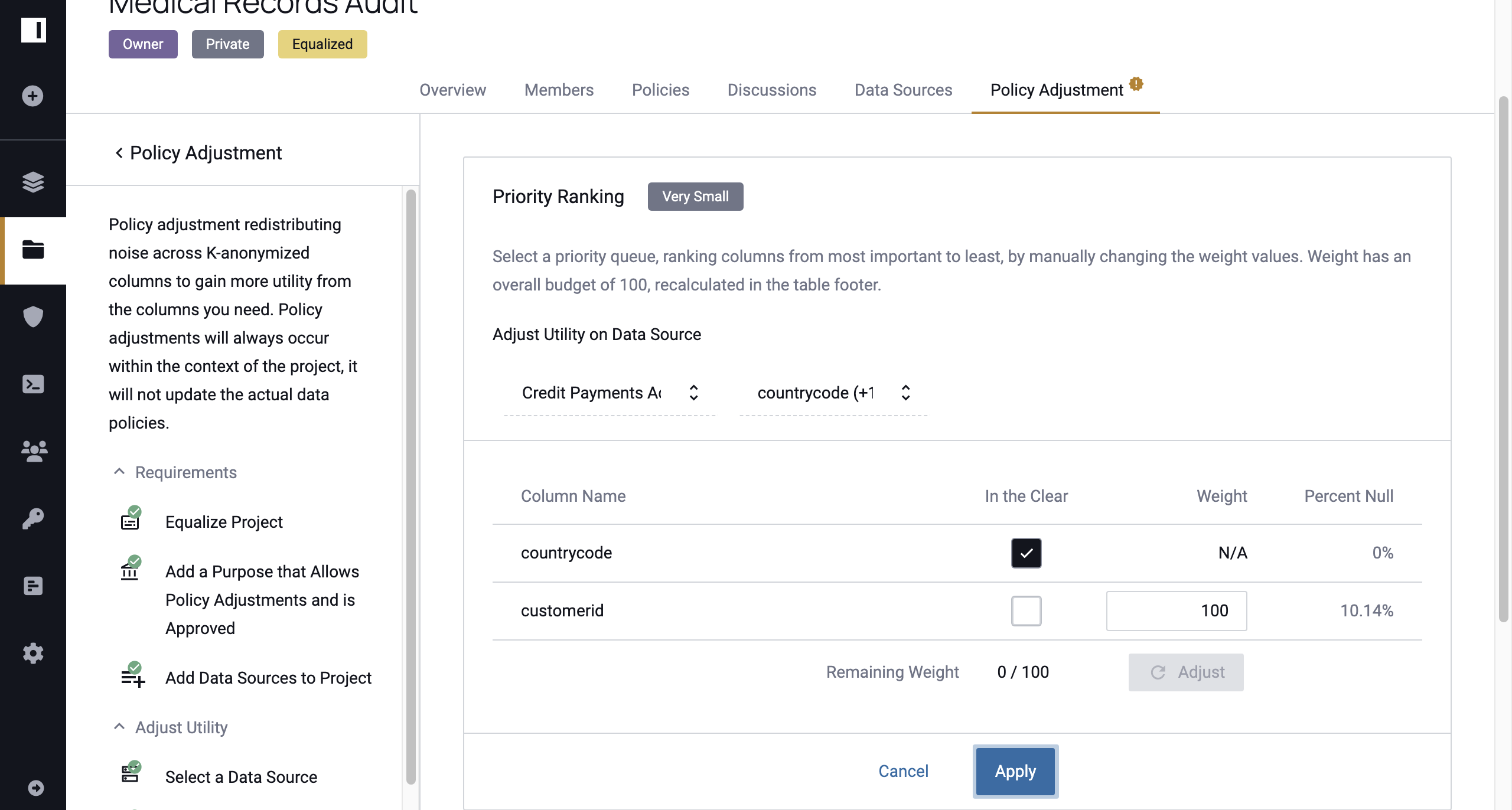
When a user queries this data source while acting under the project, the countrycode column will not be k-anonymized;
instead, they will see unaltered values while customerid column remains k-anonymized.