Snowflake Integration Overview
Audience: System Administrators, Data Owners, and Data Users
Content Summary: This page describes the Snowflake integration, through which Immuta applies policies directly in Snowflake. Users can use the Snowflake Web UI and their existing BI tools to query protected data natively in Snowflake.
There are two integration options:
- Snowflake Integration Using Snowflake Governance Features : With this integration, policies administered in Immuta are pushed down into Snowflake as Snowflake governance features (row access policies and masking policies).
- Snowflake Integration Without Snowflake Governance Features : With this integration, policies administered by Immuta are pushed down into Snowflake as views with a 1-to-1 relationship to the original table and all policy logic is contained in that view.
See the Snowflake integration page for a tutorial on enabling Snowflake through the App Settings page.
Snowflake Integration Using Snowflake Governance Features
Snowflake Enterprise Edition Required
This integration requires the Snowflake Enterprise Edition.
In this integration, Immuta manages access to Snowflake tables by administering Snowflake row access policies and column masking policies on those tables, allowing users to query tables directly in Snowflake while dynamic policies are enforced.
Like with all Immuta integrations, Immuta can inject its ABAC model into policy building and administration to remove policy management burden and significantly reduce role explosion.
Architecture
When an administrator configures the Snowflake integration with Immuta, Immuta creates an IMMUTA database
and schemas (immuta_procedures, immuta_policies, and immuta_functions) within Snowflake to contain
policy definitions and user entitlements. Immuta then creates a system role and gives that system account
the following privileges:
APPLY MASKING POLICYAPPLY ROW ACCESS POLICYALL PRIVILEGES ON DATABASE "IMMUTA" WITH GRANT OPTIONALL PRIVILEGES ON ALL SCHEMAS IN DATABASE "IMMUTA" WITH GRANT OPTIONUSAGE ON FUTURE PROCEDURES IN SCHEMA "IMMUTA".immuta_procedures WITH GRANT OPTIONUSAGE ON WAREHOUSEOWNERSHIP ON SCHEMA "IMMUTA".immuta_policies TO ROLE "IMMUTA_SYSTEM" COPY CURRENT GRANTSOWNERSHIP ON SCHEMA "IMMUTA".immuta_procedures TO ROLE "IMMUTA_SYSTEM" COPY CURRENT GRANTSOWNERSHIP ON SCHEMA "IMMUTA".immuta_functions TO ROLE "IMMUTA_SYSTEM" COPY CURRENT GRANTSOWNERSHIP ON SCHEMA "IMMUTA".public TO ROLE "IMMUTA_SYSTEM" COPY CURRENT GRANTS
Optional features, like automatic object tagging, native query auditing, etc., require additional permissions to be granted to the Immuta system account, which are listed on the Snowflake Features page.
Policy Enforcement
Snowflake is a policy push integration with Immuta. When Immuta users create policies, they are then pushed into the Immuta database within Snowflake; there, the Immuta system account applies Snowflake row access policies and column masking policies directly onto Snowflake tables. Changes in Immuta policies, user attributes, or data sources trigger webhooks that keep the Snowflake policies up-to-date.
For a user to query Immuta-protected data, they must meet two qualifications:
- They must be subscribed to the Immuta data source.
- They must be granted
SELECTaccess on the table by the Snowflake object owner or automatically via the Snowflake table grants feature.
After a user has met these qualifications they can query Snowflake tables directly.
Registering Data Sources
Best Practice
Use a dedicated Snowflake role to register Snowflake tables as Immuta data sources. Then, include this role in the Excepted Roles/Users list.
Register Snowflake data sources using a dedicated Snowflake role. No policies will apply to that role, ensuring that your integration works with the following use cases:
-
Snowflake Project Workspaces: Snowflake workspaces generate static views with the credentials used to register the table as an Immuta data source. Those tables must be registered in Immuta by an Excepted Role so that policies applied to the backing tables are not applied to the project workspace views.
-
Using Views and Tables within Immuta: Because this integration uses Snowflake Governance Policies, users can register tables and views as Immuta data sources. However, if you want to register views and apply different policies to them than their backing tables, those views must be registered in Immuta by an Excepted Role; otherwise, the backing table’s policies will be applied to that view.
Snowflake bulk data source creation
Private preview
This feature is only available to select accounts. Reach out to your Immuta representative to enable this feature.
Bulk data source creation is the more efficient process when loading more than 5000 data sources from Snowflake and allows for data sources to be registered in Immuta before running sensitive data discovery or applying policies.
To use this feature, see the Bulk create Snowflake data sources guide.
Resource allocations
Based on performance tests that create 100,000 data sources, the following minimum resource allocations need to be applied to the appropriate pods in your Kubernetes environment for successful bulk data source creation.
| Web | Database | Query Engine | |
|---|---|---|---|
| Memory | 4Gi | 16Gi | 8Gi |
| CPU | 2 | 4 | 2 |
| Storage | 8Gi | 24Gi | 16Gi |
Limitations
- Performance gains are limited when enabling sensitive data discovery at the time of data source creation.
- External catalog integrations are not recognized during bulk data source creation. Users must manually trigger a catalog sync for tags to appear on the data source through the data source's health check.
Excepted Roles/Users
Excepted Roles and Users are assigned when the integration is installed, and no policies will apply to these users' queries, despite any Immuta policies enforced on the tables they are querying. Credentials used to register a data source in Immuta will be automatically added to this excepted list for that Snowflake table. Consequently, roles and users added to this list and used to register data sources in Immuta should be limited to service accounts.
Immuta excludes the listed roles and users from policies by wrapping all policies in a CASE statement that will check if a user is acting under one of the listed usernames or roles. If a user is, then the policy will not be acted on the queried table. If the user is not, then the policy will be executed like normal. Immuta does not distinguish between role and username, so if you have a role and user with the exact same name, both the user and any user acting under that role will have full access to the data sources and no policies will be enforced for them.
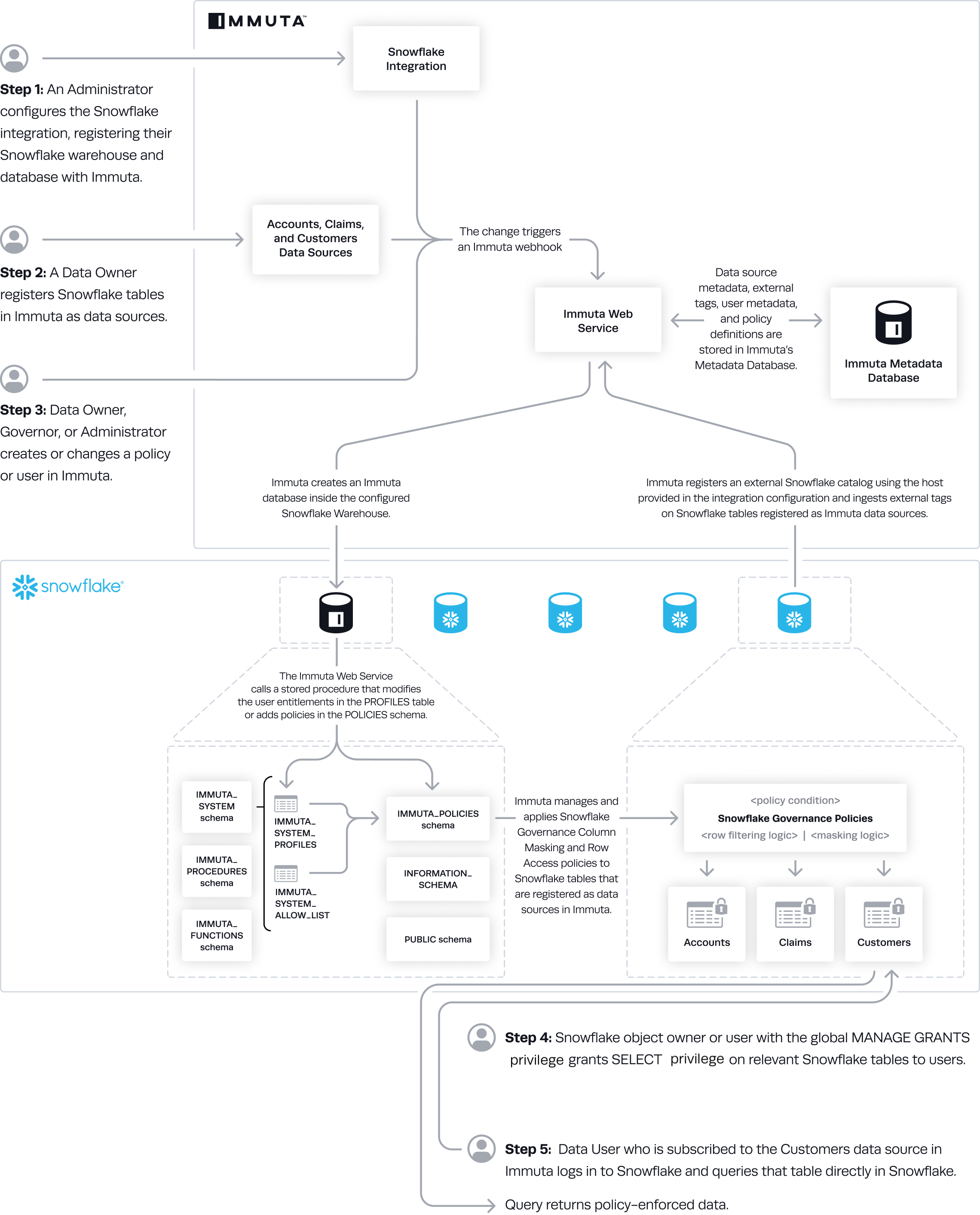
Data Flow
- An Immuta Application Administrator configures the Snowflake integration and registers Snowflake warehouse and databases with Immuta.
- Immuta creates a database inside the configured Snowflake warehouse that contains Immuta policy definitions and user entitlements.
- A Data Owner registers Snowflake tables in Immuta as data sources.
- If Snowflake tag ingestion was enabled during the configuration, Immuta uses the host provided in the configuration and ingests internal tags on Snowflake tables registered as Immuta data sources.
- A Data Owner, Data Governor, or Administrator creates or changes a policy or a user's attributes change in Immuta.
- The Immuta Web Service calls a stored procedure that modifies the user entitlements or policies.
- Immuta manages and applies Snowflake Governance column and row access policies to Snowflake tables that are registered as Immuta data sources.
- If Snowflake table grants is not enabled, Snowflake object owner or user with the global MANAGE GRANTS privilege grants SELECT privilege on relevant Snowflake tables to users. Note: Although they are GRANTed access, if they are not subscribed to the table via Immuta-authored policies, they will not see data.
- A Snowflake user who is subscribed to the data source in Immuta queries the corresponding table directly in Snowflake and sees policy-enforced data.
Snowflake Integration Without Snowflake Governance Features
In this integration, all enforcement is done by creating views that contain all policy logic. Each view has a 1-to-1
relationship with the original table.
All policy-enforced views are accessible through the PUBLIC
role and access controls are applied in the view, allowing customers to leverage Immuta's powerful set of
attribute-based policies. Additionally, users can continue using roles to enforce compute-based policies through
"warehouse" roles, without needing to grant each of those roles access to the underlying data or create
multiple views of the data for each specific business unit.
Architecture
This integration leverages webhooks to keep Snowflake views up-to-date with the corresponding Immuta data sources. Whenever a data source or policy is created, updated, or disabled, a webhook will be called that will create, modify, or delete the Snowflake view with Immuta policies.
The SQL that makes up all views includes a join to the secure
view: immuta_system.user_profile. This view is a select from the
immuta_system.profile table (which contains all Immuta users and their current groups, attributes, projects, and a
list of valid tables they have access to) with a constraint immuta__userid = current_user() to ensure it only
contains the profile row for the current user. This secure view is readable by all users and will only display the
data that corresponds to the user executing the query.
Note: The immuta_system.profile table is updated through webhooks whenever a user's groups or
attributes change, they switch projects, they acknowledge a purpose, or when their data source access is approved
or revoked. The profile table can only be read and updated by the Immuta system account.
By default, all views are created within the immuta database, which is accessible by the
PUBLIC role, so users acting under any Snowflake role can connect. All views within the database have
the SELECT permission granted to the PUBLIC role as well, and access is enforced by the access_check function
built into the individual views. Consequently, there is no need for users to manage any role-based access to any of the
database objects managed by Immuta.
Secure and Non-Secure Views
When creating a Snowflake data source, users have the option to use a regular view (traditional database view) or a secure view; however, according to Snowflake's documentation , "the Snowflake query optimizer, when evaluating secure views, bypasses certain optimizations used for regular views. This may result in some impact on query performance for secure views." To use the data source with both Snowflake and Snowflake Workspaces, secure views are necessary. Note: If HIPAA compliance is required, secure views must be used.
Non-Secure View Policy Implications
When using a non-secure view, certain policies may leak sensitive information. In addition to the concerns outlined here, there is also a risk of someone exploiting the query optimizer to discover that a row exists in a table that has been excluded by row-level policies. This attack is mentioned here in the Snowflake documentation.
Policies that will not leak sensitive information
- masking by making NULL, using a constant, or by rounding (date/numeric)
- minimization row-level policies
- date-based row-level policies
- k-anonymization masking policies
Policies that could leak sensitive information
- masking using a regex will show the regex being applied. In general this should be safe, but if you have a regex
policy that removes a specific selector to redact (e.g., a regex of
/123-45-6789/gto specifically remove a single SSN from a column), then someone would be able to identify columns with that value. - in conditional masking and custom WHERE clauses including “Right To Be Forgotten,” the custom SQL will be visible, so for a policy like "only show rows where COUNTRY NOT IN(‘UK’, ‘AUS’)," users will know that it’s possible there is data in that table containing those values.
Policies that will leak potentially sensitive information
These policies leak information sensitive to Immuta, but in most cases would require an attacker to reverse the algorithm. In general these policies should be used with secure views:
- masking using hashing will include the salt used
- numeric and categorical randomized response will include the salt used
- reversible masking will include both a key and an IV
- format preserving masking will include a tweak, key, an alphabet range, prefix, pad to length, and checksum id if used
Policy Enforcement
The data sources themselves have all the Data policies included in the SQL through a series of CASE statements that
determine which view of the data a user will see. Row-level policies are applied as top-level WHERE clauses,
and usage policies (purpose-based or subscription-level) are applied as WHERE clauses against the user_profile JOIN.
The access_check function allows Immuta to throw custom errors when a user lacks access
to a data source because they are not subscribed to the data source, they are operating under the wrong project, or
they cannot view any data because of policies enforced on the data source.