Create a Query-Backed Data Source
Audience: Data Owners
Content Summary: Query-backed data sources are accessible to subscribed Data Users through the Immuta Query Engine and appear as though they are Postgres tables. Although these files look like they are local, reading a file executes a query to the remote storage system or the Immuta caching layer for that file. The Immuta policies are put into action either through querying the remote database or filtering automatically.
For a complete list of supported databases, see the Immuta Support Matrix.
Note
This page contains references to the term whitelist, which Immuta no longer uses. When the term is removed from the software, it will be removed from this page.
Redshift data sources
- Redshift Spectrum data sources must be registered via the Immuta CLI or V2 API using this payload.
- Registering Redshift datashares as Immuta data sources is unsupported.
Requirements
CREATE_DATA_SOURCEImmuta permission- Snowflake data source requirements:
USAGESnowflake privilege on the schema and databaseREFERENCESSnowflake privilege on the tables
1 - Create a New Data Source
- Click the plus button in the top left of the Immuta console.
- Select New Data Source.
Alternatively,
- Navigate to the My Data Sources page.
- Click the New Data Source button in the top right corner.
2 - Select Your Storage Technology
Select the storage technology containing the data you wish to expose by clicking a tile.
Required Google BigQuery roles for creating data sources
Ensure that the user creating the Google BigQuery data source has these roles:
roles/bigquery.metadataVieweron the source table (if managed at that level) or datasetroles/bigquery.dataViewer(or higher) on the source table (if managed at that level) or datasetroles/bigquery.jobUseron the project
3 - Enter Connection Information
Best Practice: Connections Use SSL
Although not required, it is recommended that all connections use SSL. Additional connection string arguments may also be provided.
Note: Only Immuta uses the connection you provide and injects all policy controls when users query the system. In other words, users always connect through Immuta with policies enforced and have no direct association with this connection.
-
Input the connection parameters to the database you're exposing. Click the tabs below for guidance for select storage technologies.
BigQuery
See the Create a Google BigQuery data source guide for instructions.
Databricks
User Requirements to Expose a Table or View
When exposing a table or view from an Immuta-enabled Databricks cluster, be sure that at least one of these traits is true:
- The user exposing the tables has READ_METADATA and SELECT permissions on the target views/tables (specifically if Table ACLs are enabled).
- The user exposing the tables is listed in the
immuta.spark.acl.whitelistconfiguration on the target cluster. - The user exposing the tables is a Databricks workspace administrator.
-
Complete the first four fields in the Connection Information box:
- Server: hostname or IP address
- Port: port configured for Databricks, typically port 443
- SSL: when enabled, ensures communication between Immuta and the remote database is encrypted
- Database: the remote database
-
Retrieve your Personal Access Token:
- Navigate to Databricks in your browser, and then click the user account icon in the top right corner of the page.
- Select User Settings from the dropdown menu.
- Navigate to the Access Tokens tab, and then click the Generate New Token button.
- When creating a Databricks Personal Access Token, using a non-expiring token is recommended so that access to the data source is not lost unexpectedly.
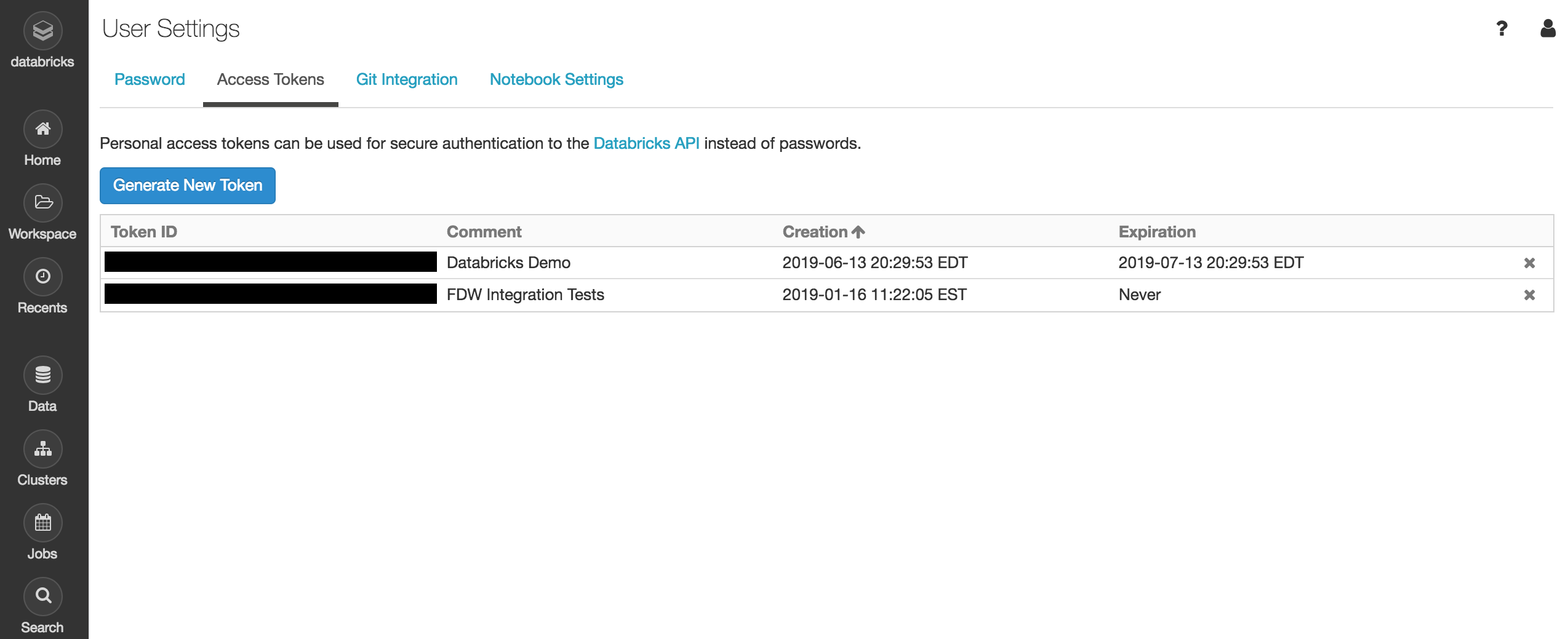
- Enter this token in the Personal Access Token field in the Immuta console.
-
Retrieve the HTTP Path.
- Navigate to your cluster in Databricks.
- Click Advanced at the bottom of the page, and then select the JDBC/ODBC tab.
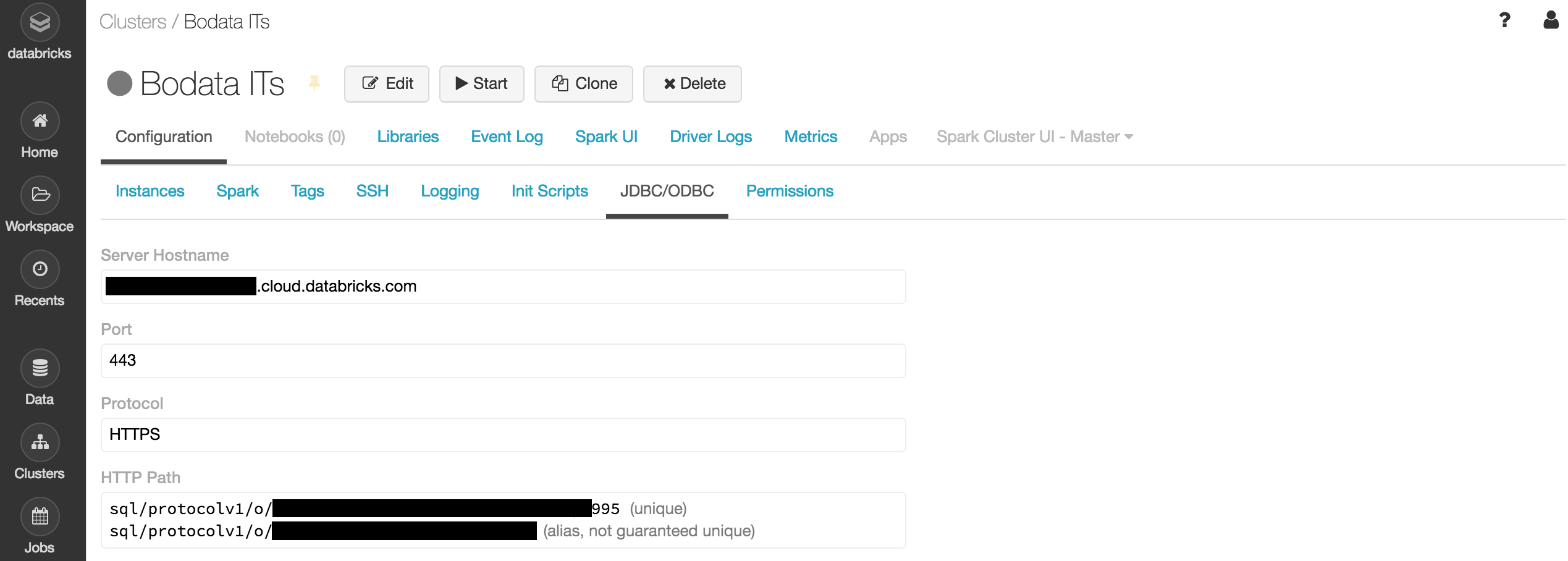
- Enter the unique HTTP Path from this page in the HTTP Path field in the Immuta console.
-
You can then choose to enter Additional Connection String Options or Upload Certificates to connect to the database.
-
Click the Test Connection button.
If the connection is successful, a check mark and successful connection notification will appear and you will be able to proceed. If an error occurs when attempting to connect, the error will be displayed in the UI. In order to proceed to the next step of data source creation, you MUST be able to connect to this data source using the connection information that you just entered.

Further Considerations
- Immuta pushes down joins to be processed on the native database when possible. To ensure this happens, make sure the connection information matches between data sources, including host, port, ssl, username, and password. You will see performance degradation on joins against the same database if this information doesn't match.
- Some storage technologies require different connection information than pictured in this section. Please refer to the tool-tips in the Immuta UI for this step if you need additional guidance.
- If you are creating an Impala data source against a Kerberized instance of Impala, the username field locks down to your Immuta username unless you possess the IMPERSONATE_HDFS_USER permission.
- If a client certificate is required to connect to the source database, you can add it in the Upload Certificates section at the bottom of the form.
4 - Select Virtual Population
-
Decide how to virtually populate the data source by selecting Create sources for all tables in this database and monitor for changes or Schema/Table.

-
Complete the workflow for Create sources for all tables in this database and monitor for changes or Schema/Table selection, which are outlined on the tabs below:
Create sources for all tables in this database and monitor for changes
Selecting this option will create and keep in sync all data sources within this database. New schemas will be automatically detected and the corresponding data sources and schema projects will be created.
- Select Create sources for all tables in this database and monitor for changes.
Schema/Table
Selecting this option will create and keep in sync all tables within the schema(s) selected. No new schemas will be detected.
- If you choose Schema/Table, click Edit in the table selection box that appears.
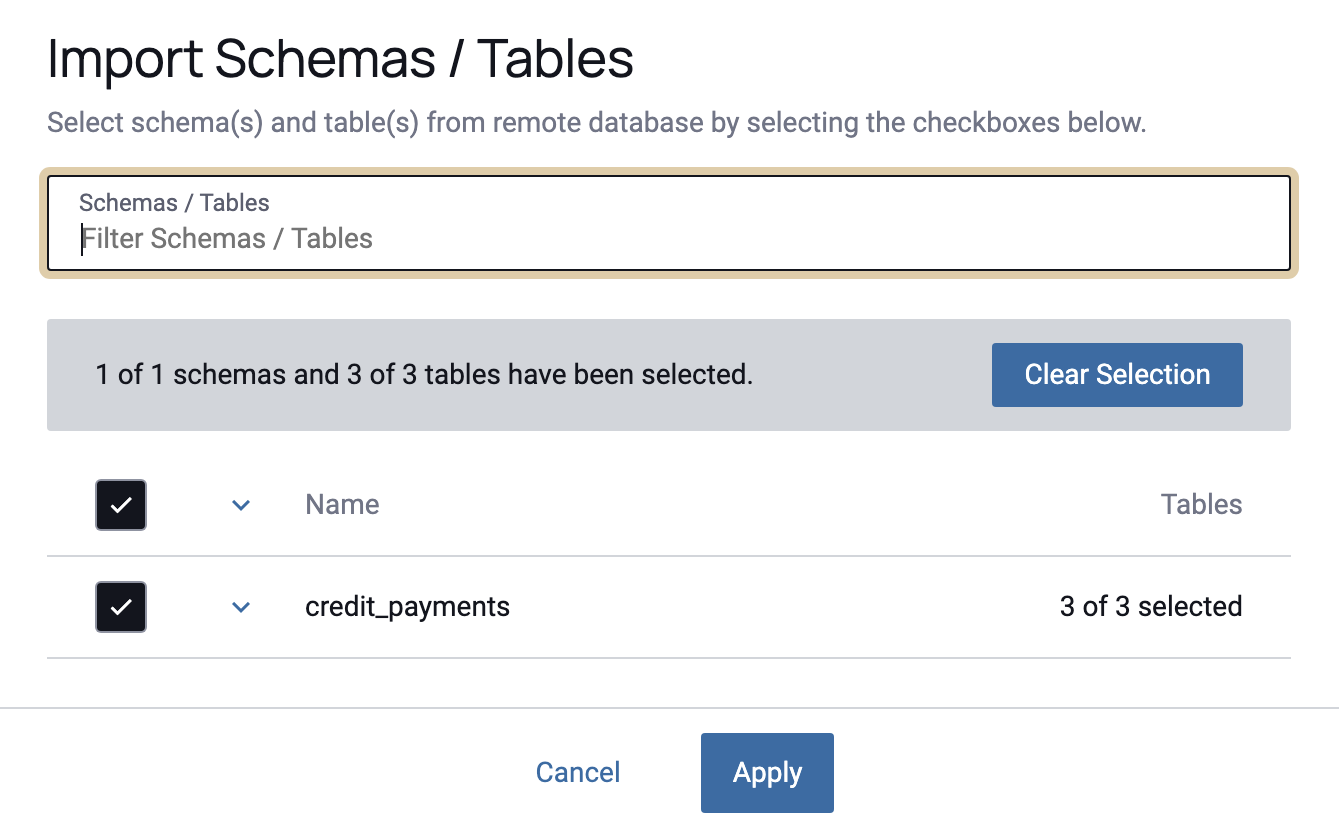
-
By default, all schemas and tables are selected. Select and deselect by clicking the checkbox to the left of the name in the Import Schemas/Tables menu. You can create multiple data sources at one time by selecting an entire schema or multiple tables.
-
After making your selection(s), click Apply.
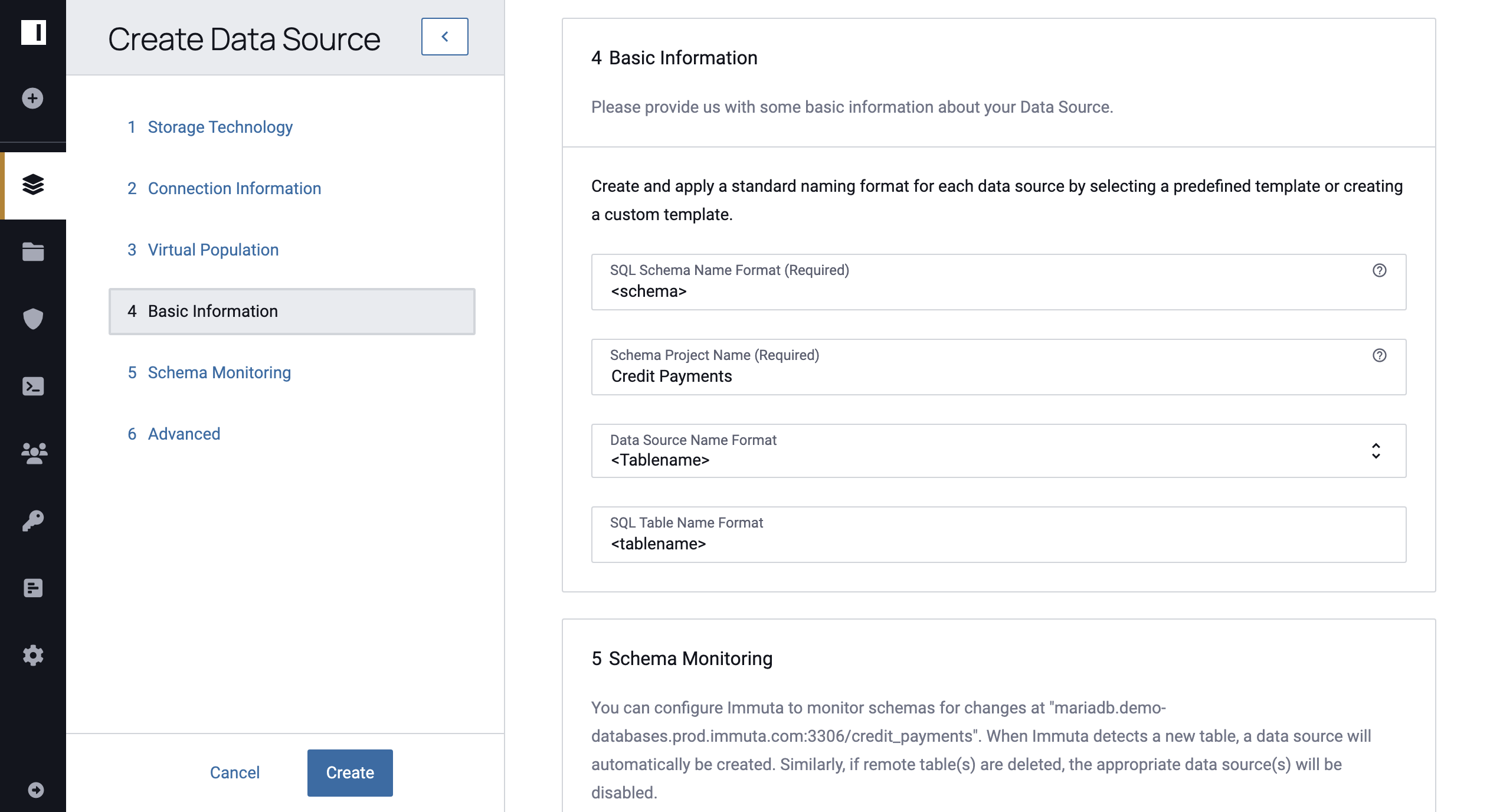
5 - Enter Basic Information
Provide information about your source to make it discoverable to users.
- Enter the SQL Schema Name Format to be the SQL name that the data source exists under in the Immuta Query Engine. It must include a schema macro but you may personalize it using lowercase letters, numbers, and underscores to personalize the format. It may have up to 255 characters.
-
Enter the Schema Project Name Format to be the name of the schema project in the Immuta UI. This field is disabled if the schema project already exists within Immuta.
- When selecting Create sources for all tables in this database and monitor for changes you may personalize this field as you wish, but it must include a schema macro.
- When selecting Schema/Table this field is prepopulated with the recommended project name and you can edit freely.
-
Select the Data Source Name Format, which will be the format of the name of the data source in the Immuta UI.
<
Tablename>The data source name will be the name of the remote table, and the case of the data source name will match the case of the macro.
<
Schema><Tablename>The data source name will be the name of the remote schema followed by the name of the remote table, and the case of the data source name will match the cases of the macros.
Custom
Enter a custom template for the Data Source Name. You may personalize this field as you wish, but it must include a tablename macro. The case of the macro will apply to the data source name (i.e., <
Tablename> will result in "Data Source Name," <tablename> will result in "data source name," and <TABLENAME> will result in "DATA SOURCE NAME").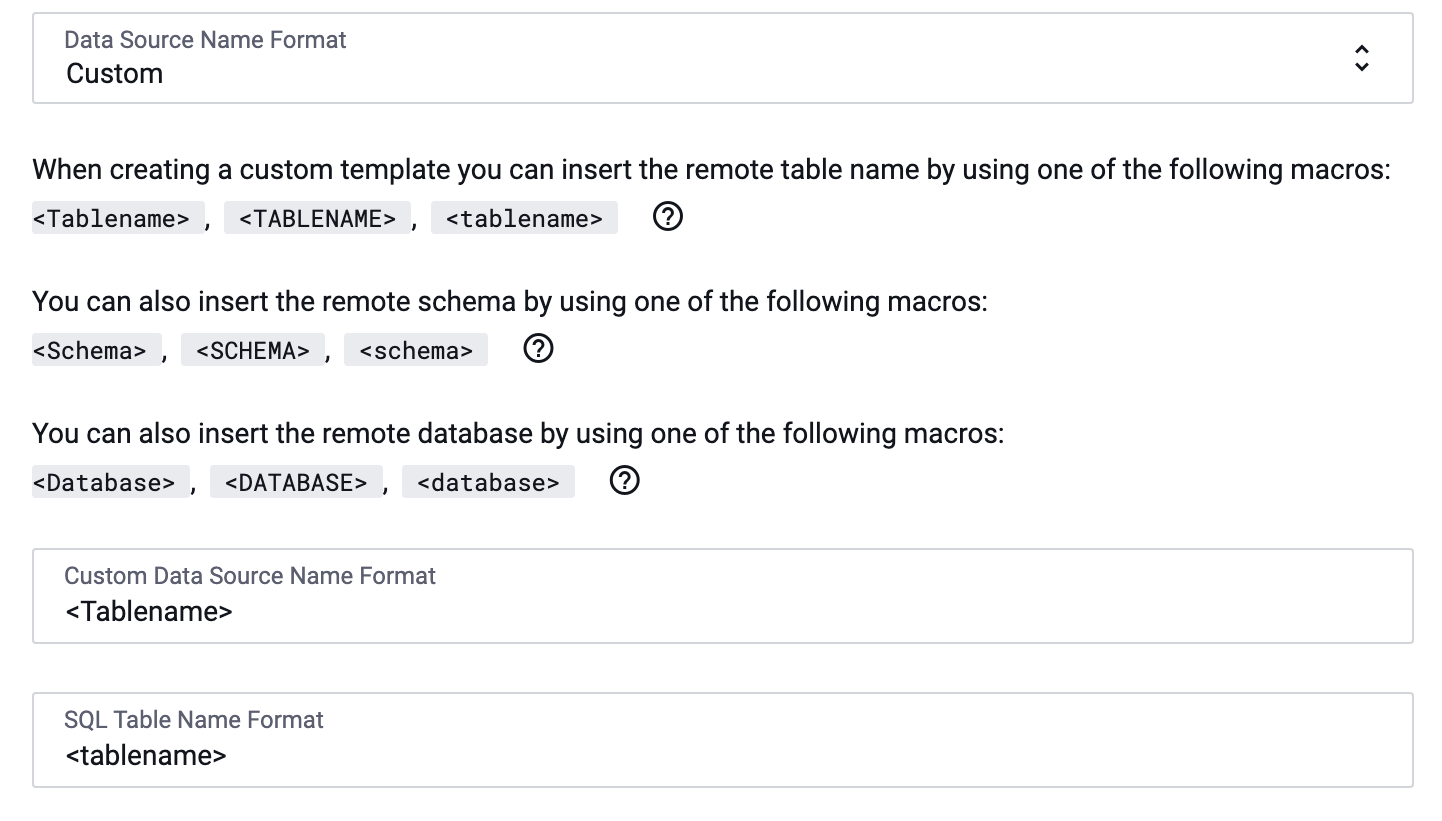
-
Enter the SQL Table Name Format, which will be the format of the name of the table in the Immuta Query Engine. It must include a table name macro, but you may personalize the format using lowercase letters, numbers, and underscores. It may have up to 255 characters.
6 - Enable or Disable Schema Monitoring
When selecting the Schema/Table option you can opt to enable Schema Monitoring by selecting the checkbox in this section.
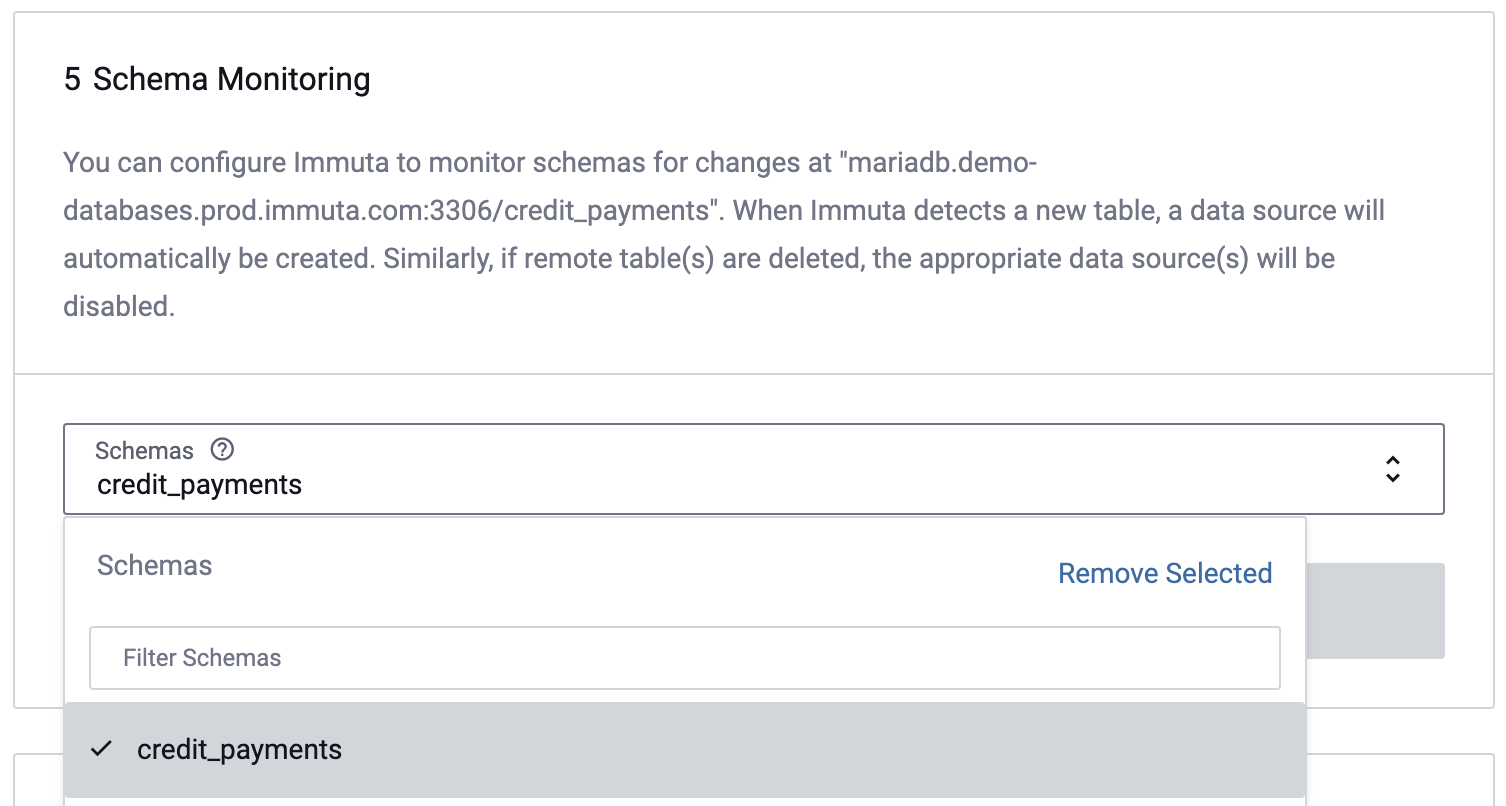
Note: This step will only appear if all tables within a server have been selected for creation.
Create a Schema Detection Job in Databricks
In most cases, Immuta’s schema detection job runs automatically from the Immuta web service. For Databricks, that automatic job is disabled because of the ephemeral nature of Databricks clusters. In this case, Immuta requires users to download a schema detection job template (a Python script) and import that into their Databricks workspace.
Generate Your Immuta API Key
Before you can run the script referenced in this tutorial, generate your Immuta API Key from your user profile page. The Immuta API key used in the Databricks notebook job for schema detection must either belong to an Immuta Admin or the user who owns the schema detection groups that are being targeted.
-
Enable Schema Monitoring or Detect Column Changes on the Data Source creation page.
-
Click Download Schema Job Detection Template.
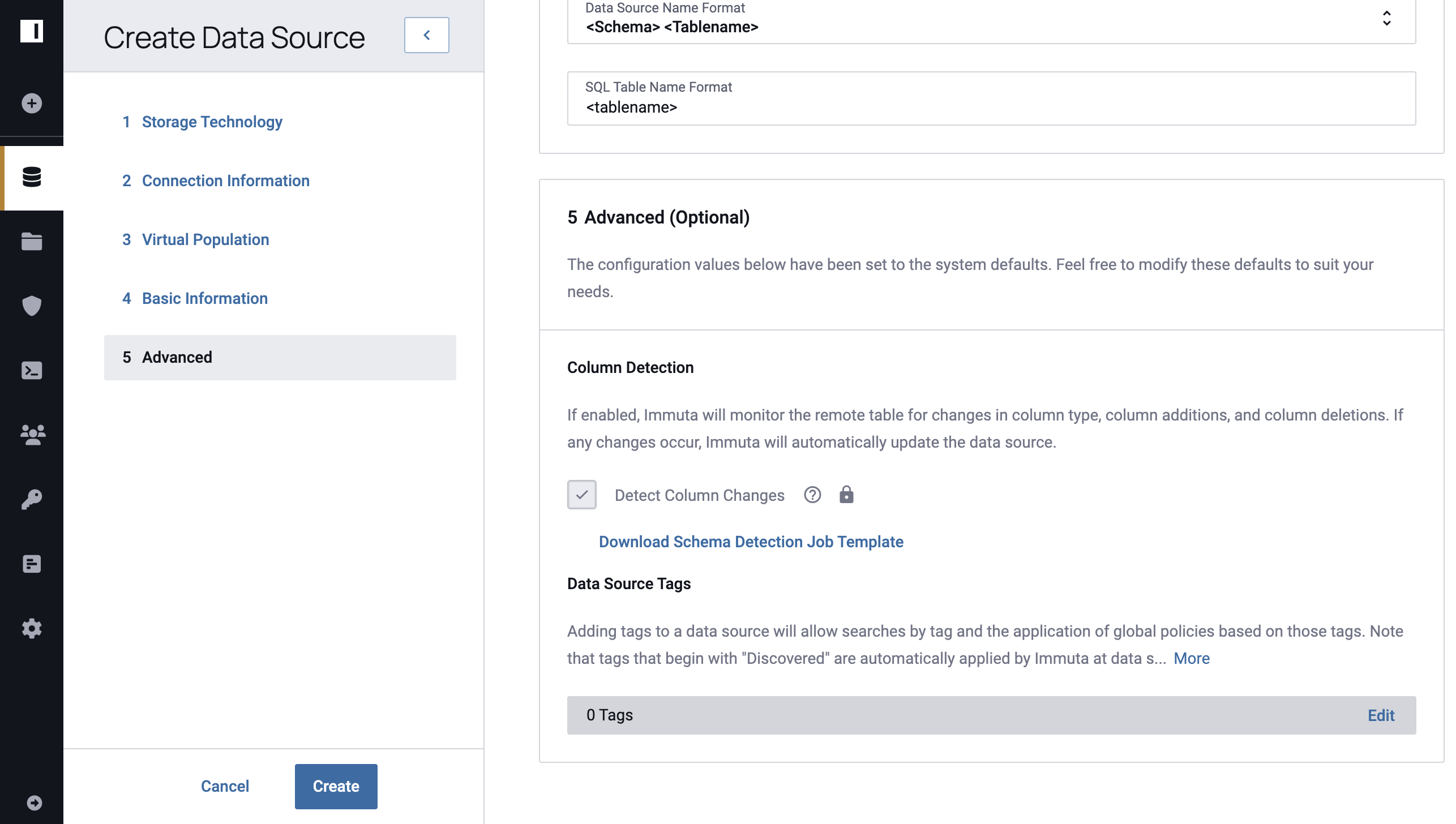
-
Click the Click Here To Download text.
-
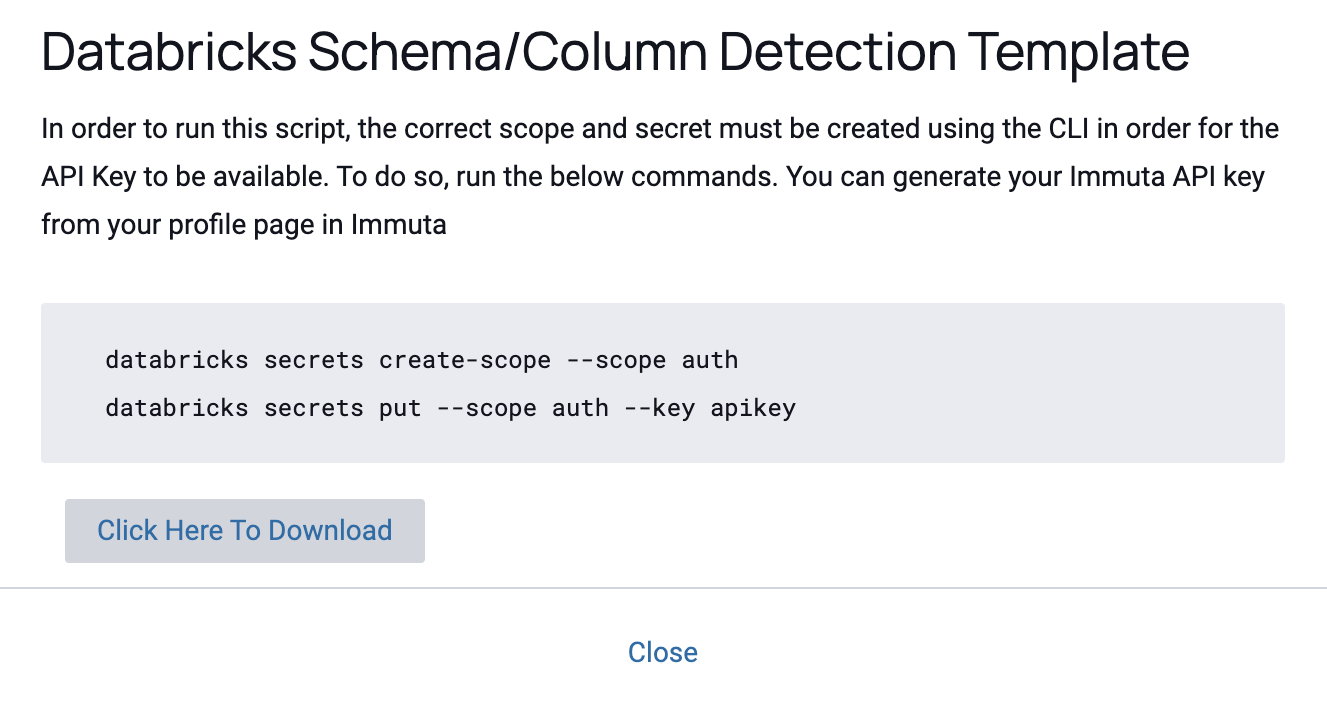
Before you can run the script, create the correct scope and secret by running these commands in the CLI using the Immuta API Key generated on your user profile page:
databricks secrets create-scope --scope auth databricks secrets put --scope auth --key apikey -
Import the Python script you downloaded into a Databricks workspace as a notebook. Note: The job template has commented out lines for specifying a particular database or table. With those two lines commented out, the schema detection job will run against ALL databases and tables in Databricks. Additionally, if you need to add proxy configuration to the job template, the template uses the Python requests library, which has a simple mechanism for configuring proxies for a request.
- Schedule the script as part of a notebook job to run as often as required. Each time the job runs, it will make
an API call to Immuta to trigger schema detection queries, and these queries will run on the cluster from which
the request was made. Note: Use the
api_immutacluster for this job. The job in Databricks must use an Existing All-Purpose Cluster so that Immuta can connect to it over ODBC. Job clusters do not support ODBC connections.
7 - Create the Data Source
Opt to configure settings in the Advanced Options section (outlined below), and then click Create to save the data source(s).
Advanced Options
None of the following options are required. However, completing these steps will help maximize the utility of your data source.
Column Detection
This setting monitors when remote tables' columns have been changed, updates the corresponding data sources in Immuta, and notifies Data Owners of these changes.

To enable, select the checkbox in this section.
See Schema Projects Overview to learn more about Column Detection.
Event Time
An Event Time column denotes the time associated with records returned from this data source. For example, if your data source contains news articles, the time that the article was published would be an appropriate Event Time column.
- Click the Edit button in the Event Time section.
- Select the column(s).
-
Click Apply.
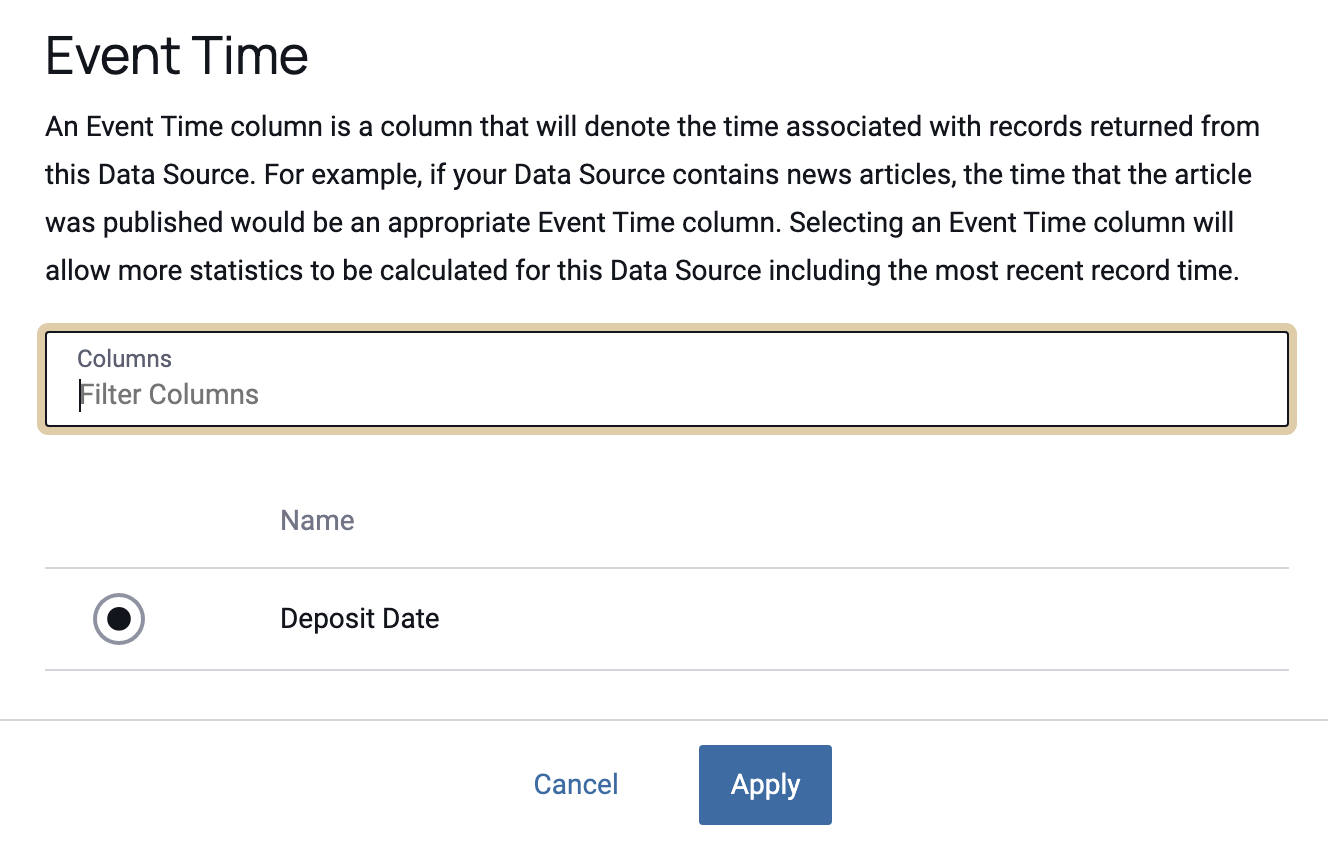
Selecting an Event Time column will enable
- more statistics to be calculated for this data source including the most recent record time, which is used for determining the freshness of the data source.
- the creation of time-based restrictions in the Policy Builder.
Latency
- Click Edit in the Latency section.
- Complete the Set Time field, and then select MINUTES, HOURS, or DAYS from the subsequent dropdown menu.
- Click Apply.
This setting impacts the following behaviors:
- How long Immuta waits to refresh data that is in cache by querying the native data source. For example, if you only load data once a day in the native source, this setting should be greater than 24 hours. If data is constantly loaded in the native source, you need to decide how much data latency is tolerable vs how much load you want on your data source; however this is only relevant to Immuta S3, since SQL will always interactively query the native database.
- How often Immuta checks for new values in a column that is driving row-level redaction policies. For example, if you are redacting rows based on a country column in the data, and you add a new country, it will not be seen by the Immuta policy until this period expires.
Sensitive Data Discovery
Data Owners can disable Sensitive Data Discovery for their data sources in this section.
- Click Edit in this section.
- Select Enabled or Disabled in the window that appears, and then click Apply.
Data Source Tags
Adding tags to your data source allows users to search for the data source using the tags and Governors to apply Global policies to the data source. Note if Schema Detection is enabled, any tags added now will also be added to the tables that are detected.
To add tags,
- Click the Edit button in the Data Source Tags section.
- Begin typing in the Search by Tag Name box to select your tag, and then click Add.
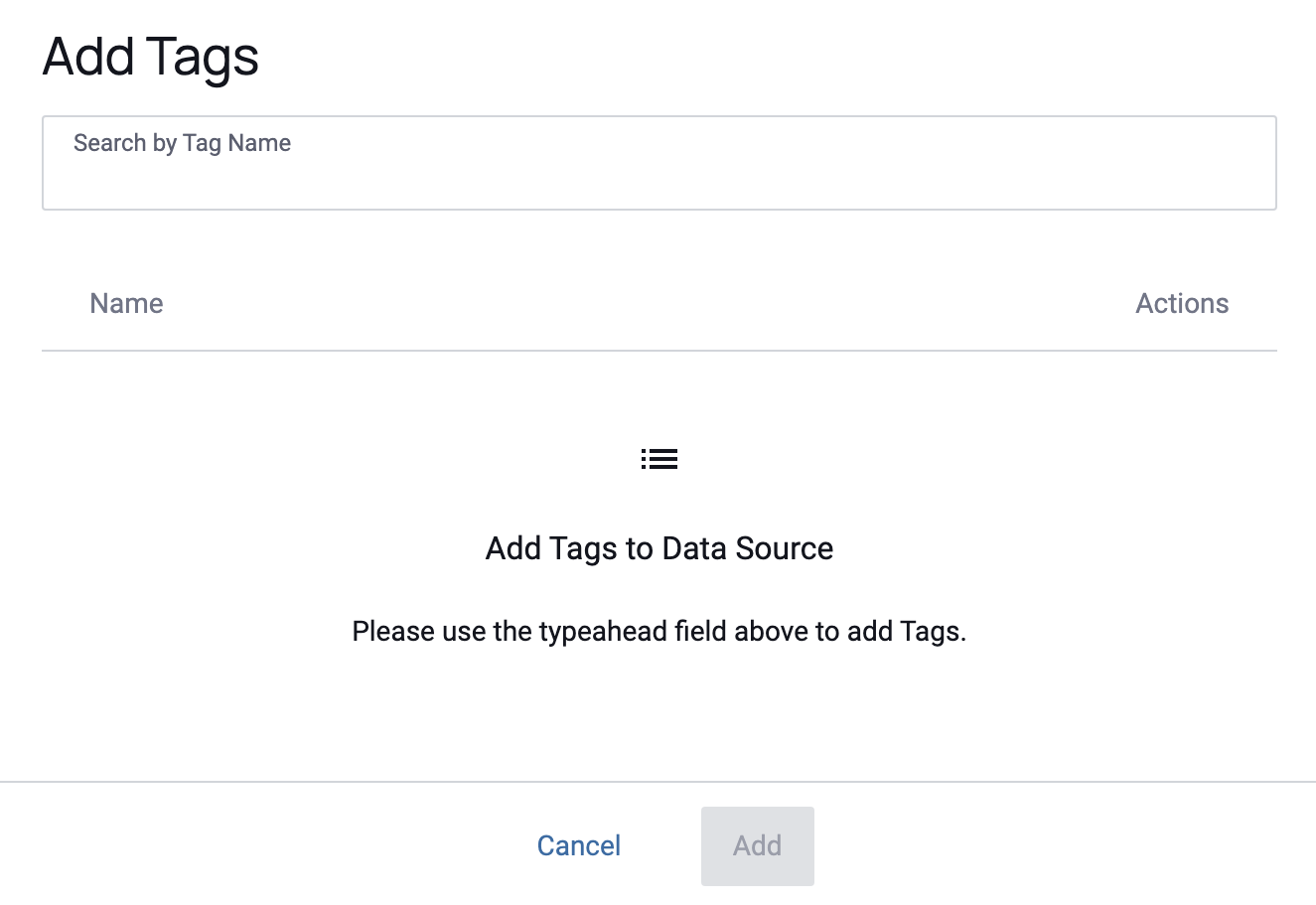
Tags can also be added after you create your data source from the Data Source details page on the Overview tab or the Data Dictionary tab.